
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 프로그래머스
- 이코테
- 정렬
- 개인회고
- 백트랙킹
- mrc
- 다시보기
- U_stage
- 그리디
- Level2
- Level2_PStage
- 알고리즘스터디
- Level1
- 글또
- python3
- dfs
- 그래프이론
- ODQA
- 최단경로
- dp
- 기술면접
- 부스트캠프_AITech3기
- 파이썬 3
- 이진탐색
- 구현
- 주간회고
- 백준
- 알고리즘_스터디
- 단계별문제풀이
- 부스트캠프_AITech_3기
- Today
- Total
국문과 유목민
[NLP] GPT 강의 정리 (Week 11) 본문
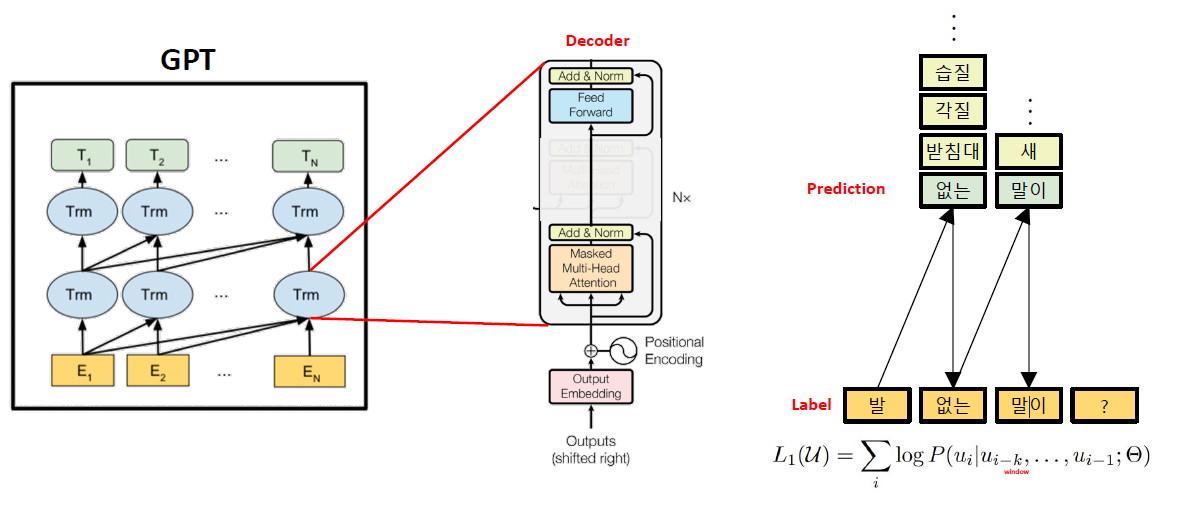
GPT
BERT는 Transformer의 인코더 구조를 사용한 모델이라면, GPT는 Transformer의 Dedcoder를 활용한 모델이다. GPT초기 모델은 BERT보다 먼저 등장해 pre-train 언어 모델의 새 지평을 열었다. 입력이 들어오면 어떤 입력이 다음으로 나올지를 생각한다. GPT는 자연어 문장을 분류하는데 아주 좋은 성능을 보여준다. 적은 양의 데이터에서도 높은 분류 성능을 나타내고, 다양한 자연어 task에서 SOTA를 달성했다.
하지만 GPT도 단점이 존재하는데 여전히 지도학습을 필요로 하며, labeled된 데이터가 필수적이라는 단점이 있었다. 그리고 특정 task를 위해서 fine-tuning된 모델은 다른 모델에서 사용이 불가능하다는 단점이 있었다. 여기서 "언어"의 특성 상, '지도학습의 목적 함수는 곧 비지도 학습에서의 목적함수와 같다'생각을 하게 된다. 즉, fine-tuning이 필요없을 것 같다는 가설을 하게 되고, 이를 통해 문제점을 개선하게 된다. 그리고 GPT모델은 엄청 큰 데이터셋을 사용하며 자연어 task를 자연스럽게 학습하게 되었다.
Few-shot Learning
인간은 새로운 task 학습을 위해 수많은 데이터를 필요로 하지 않는다. 하지만 지금까지의 모델은 Pre-train model을 fine-tuning해서 하나의 task만 수행이 가능했다. 하지만 GPT는 이를 해결하기 위해서 Few-shot Learning 방법을 제시했다. gradient update없이 단지 몇 개의 예시와 prompt만으로 Task를 수행하는 방법이다.

GPT-2
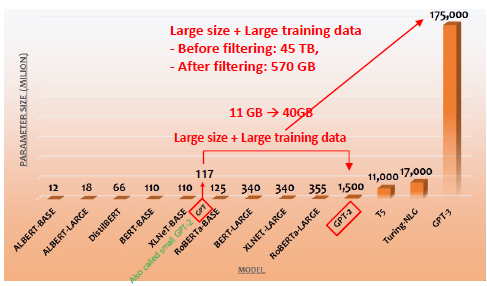
GPT-2는 단순하게 모델의 사이즈와 학습 데이터를(11GB → 40GB)를 늘려서 성능을 향상시켰다. GPT-2를 사용했을 때, 다음 단어 예측 방식에서는 SOTA성능을 보여줬다. 그리고 기계독해, 요약, 번역 등의 자연어 task에서는 일반 신경망 수준을 보였지만, Zero, One, Few-shot learning의 새 지평을 제시했다는 점에서 의미가 있는 모델이다.
GPT-3
GPT-3는 GPT-2보다 파라미터를 100배 정도로 늘리고, 학습 데이터도 40GB → 570GB으로 확 늘렸다. GPT-2와는 모델 구조가 약간 다르지만, Transformer를 사용했다는 점은 같다.
- 뉴스기사 생성: 평가자가 진짜 뉴스 기사와 GPT-3가 생성한 뉴스 기사를 구분하는 Task를 수행했는데, GPT가 만든 기사 중 88%가 실제 뉴스 기사처럼 만들어졌다는 평가를 했다고 전해진다.
GPT는 상식 Q&A나 텍스트 데이터 파싱, 특정 Task에 대한 질의응답이나 번역 등의 작업을 수행할 수 있다.
OpenAI의 Awesome GPT-3를 보면, 70개 가량의 예제를 확인해볼 수 있다.
GPT는 좋은 성능을 보여주는 모델이긴 하지만, Weight Update가 없다는 것은 모델에 새로운 지식 학습이 없다는 것을 의미한다. 그리고 이에 따라 시기가 변하면서 발생하는 문제가 생기게 된다.(나라의 대통령이나 신조어 등) 따라서 모델의 크기만 증가시키는 방식이 아닌 새로운 연구가 필요하다. 그리고 그러한 방식 중 하나로 MultiModal이 있을 수 있다.
실습
- GPT-2 자연어 생성법
- GPT-2 Few Shot Learning
- KoGPT-2 기반 챗봇
해당 실습 강의에서는 GPT-2모델을 기반으로 실제 코드가 어떤 식으로 구동되는지를 확인했다. GPT-2모델이 생성한 문장들을 보면 문법적인 구조는 꽤나 갖추었지만, 의미적인 연결성이 많이 약하다는 느낌을 많이 받았다. 학습에 사용한 데이터 양이 적었기에 생기는 문제일 것이라고 생각한다. 또한, 한국어 GPT모델의 발전이 영어 모델보다는 느릴 것이기 때문에 이 부분도 고려해야 한다. 나중에 GPT-3로 학습된 모델들을 한 번 보면 좋을 것 같다.
최근에 여러 스타트업에서 GPT를 기반으로 한 챗봇을 많이 만들고(스캐터랩[이루다], 튜닙[Blooony] 등), 관심을 갖고 있는 만큼 꾸준한 성능향상이 기대되는 분야인 것 같아 나 또한 관심이 간다.
'IT 견문록 > 추가 학습 정리' 카테고리의 다른 글
| [WandB] Huggingface 라이브러리에서 Sweep 사용하기 (0) | 2022.04.04 |
|---|---|
| [NLP] Chatbot Summary (0) | 2022.04.01 |
| [git] .gitignore 사용법 (0) | 2022.03.23 |
| [WandB] Huggingface라이브러리와 사용하기 (0) | 2022.03.23 |
| [NLP] OVERVIEW (Word2Vec to Transformer) (0) | 2022.03.21 |



