
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 파이썬 3
- dfs
- 프로그래머스
- 다시보기
- 부스트캠프_AITech3기
- dp
- python3
- 개인회고
- Level2_PStage
- 백트랙킹
- 그래프이론
- 알고리즘_스터디
- U_stage
- 기술면접
- 백준
- 부스트캠프_AITech_3기
- 그리디
- ODQA
- 단계별문제풀이
- 알고리즘스터디
- 이진탐색
- 글또
- 주간회고
- Level1
- 정렬
- Level2
- 최단경로
- 이코테
- mrc
- 구현
- Today
- Total
국문과 유목민
[일일리포트] Day 68 (Retrieval Basic) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
Passage Retrieval
질문(query)에 맞는 문서(Passage)를 찾는 것을 Passage Retrieval 이라고 한다. MRC Task에서 Passage Retrieval에는 ODQA(Open-Domain Question Answering)가 있다. ODQA는 대규모의 문서 중에서 질문에 대한 답을 찾는 것으로, Passage Retrieval와 MRC를 이어 2-Stage로 만든다. Passage Retrieval을 간단히 정리하자면, Query와 Passage를 임베딩한 뒤 유사도로 랭킹을 매기고 유사도가 가장 놓은 Passage를 선택하는 과정으로 정리할 수 있다.
Passage Embedding
Passage Embedding은 구절(Passage)을 벡터로 변환하는 것을 의미한다. Passage Embedding Space는 Passage Embedding의 벡터 공간을 의미한다. 벡터화된 Passage를 이용해 Passage 간 유사도 등 알고리즘을 계산할 수 있다. Passage Embedding 방식에는 Sparse Embedding과 Dense Embedding이 존재하는데, 우선 Sparse Embedding에 대해 알아보겠다.
Sparse Embedding
Sparse Embedding의 가장 대표적인 방법으로는 Bag-of-Words(BoW)가 있다. BoW를 n-gram으로 구성할 수 있는데, 기존 unigram으로 하는 것보다 bigram으로 advanced하게 설정할 수 있다. 단, n-gram이 늘어나면 늘어날수록 BoW의 크기가 더 커진다. Sparse Embedding은 Term overlap을 정확하게 잡아낼 때 유용하다. 하지만, 등장하는 단어가 많아수록 차원이 커지고, 의미가 비슷하지만 다른 단어의 경우 비교가 불가능하다.
그래서 이러한 문제를 개선한 방법으로 Term Value를 결정하는 TF-IDF가 있다. TF-IDF (Term Frequency-Inverse Document Frequency)는 단어의 등장빈도(Term Frequency)를 나타내는 TF와 단어가 제공하는 정보의 양(Inverse Document Frequency)을 나타내는 IDF를 활용해 계산하는 방법이다. 좀 더 많은 정보를 제공하는 단어들이 IDF 스코어가 더 높게 나온다. (그 정보의 기준을 어떻게 정하는지는 밑에서 설명)
- TF: 해당 문서 내 단어의 등장 빈도. Raw count를 그대로 쓰지는 않고, 전체 텍스트 내에서 비율(raw count / num words)을 정한다. variants로 binary나 log normalization을 할 수도 있다.
- IDF: 단어가 제공하는 정보의 양을 의미한다. IDF의 공식은 다음과 같다.
$$IDF(t)=log\frac{N}{DF(t)}$$
DF(Document Frequency): Term t가 등장한 document의 개수
N: 총 document의 개수. 만약 모든 문장에 다 등장하는 단어는 IDF가 0이 된다.
앞서 계산한 TF와IIDF의 식을 연결하기 위해서는 단순히 product해주기만 하면은 된다. TF-IDF(t,d)의 의미는 다음과 같다. 'TF-IDF for term t in document d'
$$\text{TF-IDF(t,d)}= TF(t, d) \times IDF(t)$$
조금 더 설명을 보태자면, 관사(a, the)는 TF는 높을 수 있지만 IDF가 0에 가깝기 때문에 전체적인 TF-IDF값이 감소한다. 하지만 자주 등장하지 않는 고유명사(사람이름, 지명 등)는 TF는 작을 수 있지만, IDF가 커지면서 전체적인 TF-IDF값이 증가한다. 따라서 여기서 얘기하는 정보의 양은 다른 문장에서 나타나지 않은 정보를 의미한다고 볼 수 있을 것 같다.
추가적으로 IDF 값은 문서에 상관없이 항상 일정한 값을 가지게 된다. 각 문서가 가지고 있는 고유한 단어가 높은 TF-IDF값을 가진 것을 확인할 수 있다.
우리가 TF-IDF를 계산함으로써 이를 활용해 사용자가 물어본 질의에 대해 가장 유사한 문서를 검색하는 Task를 수행해볼 수 있다.
BM-25
TF-IDF에서 발전된 방법으로 BM-25가 있다. TF-IDF의 개념을 바탕으로, 문서의 길이를 더 고려해 점수를 매긴다. 평균적인 문서의 길이보다 더 작은 길이의 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여하는 방식이다. 실제 검색엔진, 추천 시스템 등에서 TF-IDF보다 더 많이 사용되는 알고리즘이다. (이번 프로젝트에서 TF-IDF를 개선시키고자 한다면 해당 공식을 사용해보는 것도 좋아보인다)
Dense Embedding
Sparse 임베딩의 단점은 차원의 수가 매우 크다는 것(Compressed format으로 극복가능)과 유사성을 고려하지 못한다는 것이다. 이러한 단점을 보완하기 위해 Dense Embedding을 사용할 수 있다. Dense Embedding은 더 작은 차원의 고밀도 벡터를 사용하고, 각 차원이 특정 Term에 대응되지 않으며, 대부분의 요소가 non-zero값이라는 특징을 가진다. 각 Embedding의 장단점을 다음과 같이 정리할 수 있다.
- SprseEmbedding: 중요한 term들이 정확히 일치해야 하는 경우 성능이 뛰어남. 임베딩이 구축되고 나서는 추가적인 학습이 불가능하다.
- Dense Embedding: 단어의 유사성 또는 맥락을 파악해야 하는 경우 성능이 뛰어남. 학습을 통해 임베딩을 만들며 추갖거인 학습 또한 가능하다. 최근 사전학습 모델이 등장함에 따라, 검색 기술의 발전 등으로 인해 Dense Embedding의 이용이 활발하다.
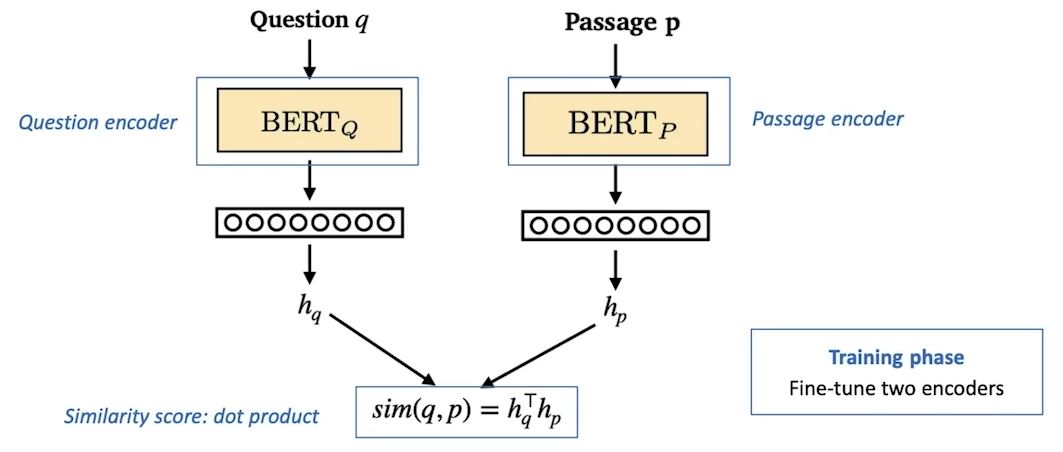
Dense Embedding OverView를 간단히 살펴보면 보면. Dense Embedding을 생성한 인코더 훈련단계와 질문과 문서를 비교하여 관련 문서 추출하는 단계로 이뤄져 있다.
Dense Encoder를 훈련하는 방법으로 BERT와 같은 Pre-trained language(PLM)을 Finetuning해서 자주 사용한다. 추가적으로 그 외 다양한 neural network 구조도 가능하다. Dence Encoder의 학습 목표와 Challenge는 다음과 같다.
- 학습목표: 연관된 Question과 Passage Dense Embedding간 거리를 좁히는 것.
- Challenge: 연관된 Question/Passage를 어떻게 찾을 것인가? → 기존 MRC데이터셋을 활용한다 (기존 데이터셋에 있으면 연관, 없으면 연관 X)
관련이 없는 Passage를 Sampling하기 위해서는 한 쪽은 거리를 좁히고, 한 쪽은 거리를 멀리해야 할 필요가 있다. 그렇게 하기 위해 Negative Sampling을 할 수 있다.
- Positive: 연관된 question과 passage간 dense embedding 거리를 좁히는 것
- Negative: 연관되지 않은 question과 passage간 embedding 거리를 멀리하는 것
Negative Samplig을 할 수 있는 방법으로는 두 가지 방법이 있다. 하나는 Corpus 내에서 랜덤하게 뽑는 방법이고, 다른 하나는 좀 더 헷갈리는 negative 샘플들 뽑는 방법이다. 예를 들어 높은 TF-IDF스코어를 가지지만, 답을 포함하지 않는 샘플의 경우 모델입장에서 구분하기 어렵기 때문에 이러한 Negative 샘플들을 뽑는 방법이 있다. 그리고 최근 연구에서 이 방법을 사용해서 정확도를 높인 Case가 있다고 한다.
Objective function으로는 Positive passage에 대한 Negative log likelihood(NLL) loss 사용한다. Evaluation Metric으로 Top-k retrieval accuracy를 활용한다. Top-k retrieval accuracy는 retreieve된 Passage 중에 답을 포함하는 passage의 비율을 의미한다.
Passage Retrieval with Dense Encoder
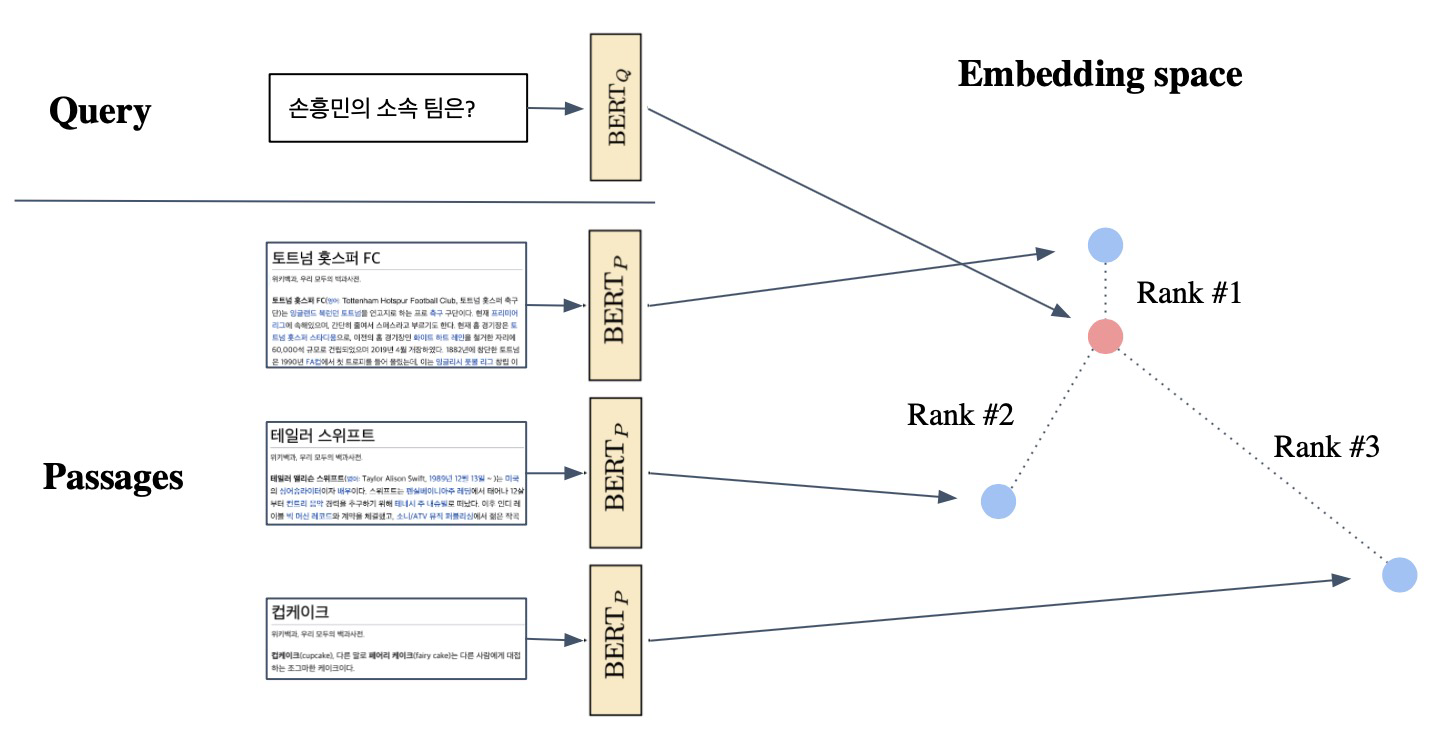
From dense encoding to retrieval: Inference를 보면 Pasasge와 Query를 각각 embedding한 후, query로부터 가까운 순대로 Passage의 순위를 매긴다.
From retrieval to open-domain question answering: Retriever를 통해 찾아낸 Passage를 활용해서 MRC모델로 답을 찾는다.
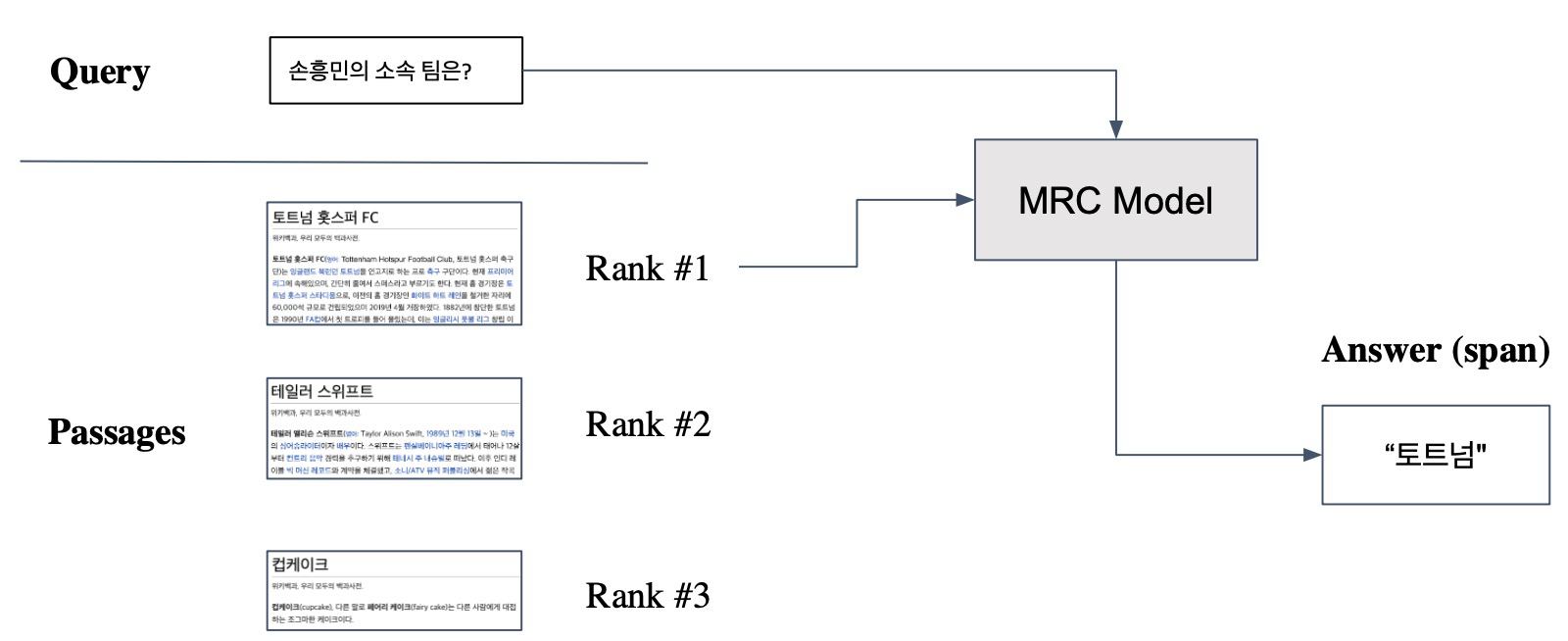
Dense Encoding개선 방법
- 학습 방법 개선 (DPR)
- 인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained 모델)
- 데이터 개선 (더 많은 데이터, 전처리 등)
MRC모델의 성능을 높이는 것도 좋지만, Retrieval의 성능을 올리는 것도 중요하다
▶ Review (생각)
오늘로 이번 주 할당된 MRC관련 강의를 다 들어서 내일 과제 2개만 하면 프로젝트로 바로 들어갈 것 같다. 이번 강의에서 배운 내용 중 우리 프로젝트에서 추가적으로 적용시킬 수 있을만한 부분이 있었다. BM-25라든가, DenseEncoder 부분의 경우 시도해볼만 한 것 같다. 아직, 오피스아워 전이기 때문에 그 전까지 다양한 방법을 생각해보면 좋을 것 같다. 그리고 추가적으로 내일 들은 나머지 2강에 대해서 정리하고, 남은 과제도 다 정리할 계획이다.
추가적으로 내일 멘토링 전까지 이력서를 수정해서 멘토님께 피드백을 받아봐야겠다. 그리고 정처기 실기도 이제 딱 10일 남아서 빨리 준비해야겠다. 이번 주부터 MRC프로젝트, 이력서, 자격증, 최종 프로젝트 준비 등 해야할 일이 많은데 지치지 않게 컨디션 관리 잘 해야겠다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 70 (Level2_MRC_1) (0) | 2022.04.28 |
|---|---|
| [일일리포트] Day 69 (Scaling Up & Linking) (0) | 2022.04.27 |
| [일일리포트] Day 67 (MRC Basic) (0) | 2022.04.25 |
| [14주차] 개인 회고 (데이터 제작 Week 2) (2) | 2022.04.22 |
| [일일리포트] Day 66 (프로젝트 정리/발표) (0) | 2022.04.22 |



