
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- dp
- Level2_PStage
- python3
- 글또
- 프로그래머스
- 주간회고
- 그리디
- 단계별문제풀이
- 부스트캠프_AITech_3기
- 기술면접
- dfs
- 알고리즘스터디
- Level1
- 파이썬 3
- U_stage
- 백준
- 구현
- 이진탐색
- 정렬
- 그래프이론
- 최단경로
- ODQA
- 알고리즘_스터디
- 이코테
- 다시보기
- Level2
- 백트랙킹
- mrc
- 부스트캠프_AITech3기
- 개인회고
- Today
- Total
국문과 유목민
[일일리포트] Day 77 (Lelvel2_MRC_7) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
논문 읽기
어제까지 DPR관련 논문을 읽어서 오늘 구현을 진행하려고 했다. 다른 팀원분과 같이 오전까지 보고 Task를 나눠서 진행하려고 계획했는데, 사정이 생겨 오전 중에 DPR 파트를 진행하지 못하고 아예 넘겨드리게 됐다. 그래서 남은 Task 중 Curriculum Learning을 진행하고자 정보를 찾아봤다.
유튜브에서 [Open DMQA Seminar] Curriculum learning - YouTube를 통해 개괄적인 부분을 이해하고자 했다. 하지만 주로 다루고 있는 Task가 CV쪽이다보니 NLP Task에서는 어떻게 다뤄야할 지 감이 잘 안 와서 Papers with code를 찾고, 팀원분께 여쭤보면서 Curriculum Learning for Natural Language Understanding 논문을 읽게 됐다.
Curriculum Learning for Natural Language Understanding
이번에 읽은 논문은 커리큘럼 러닝(CL)을 NLU Task에 접목시키는 방법이다. CL은 쉬운 걸 먼저 학습하고, 이후에 난이도를 높여서 인간이 학습하는 방법처럼 모델에도 쉬운 데이터를 먼저 학습시키고 이후에 어려운 데이터를 학습시키는 방식이다.
해당 논문에서는 데이터셋으로 학습을 시킬 때 난이도 검토 방법(Difficulty Review Method)과 커리큘럼 배열 알고리듬으로 구성된 새로운 CL 프레임워크를 제안한다. 해당 CL 프레임워크 방법은 광범위한 NLU Task(MRC, NLI)를 포함하며, 모든 Task에서 성능 향상을 이끌어낼 수 있었다고 한다. (이번 대회에서 Reader모델의 Task가 MRC(Machine Reading Comprehension)이기 때문에 해당 부분에 대해서만 다뤄보고자 한다)
CL에서 가장 어렵다고 생각했던 부분 중 하나가 난이도를 어떻게 설정할 것인가 하는 부분이었다. 해당 논문에서는 난이도 설정을 위해 Golden Metric이라는 것을 사용했고, 해당 Metric은 NLP Task별로 기준이 달라졌다. 예를 들어 MRC는 F1, Sequence Classification은 Accuracy처럼 달라진다.
난이도 측정은 데이터셋을 N개로 나누고, 해당 데이터셋을 학습한는 모델(Teacher 모델이라고 지칭) N개를 만들어낸다. 그러면 총 N개의 Inference파일이 생긴다. 이렇게 나온 결과를 가지고 Cross Review라는 과정을 통해 난이도 점수(difficulty score)를 계산한다고 한다.
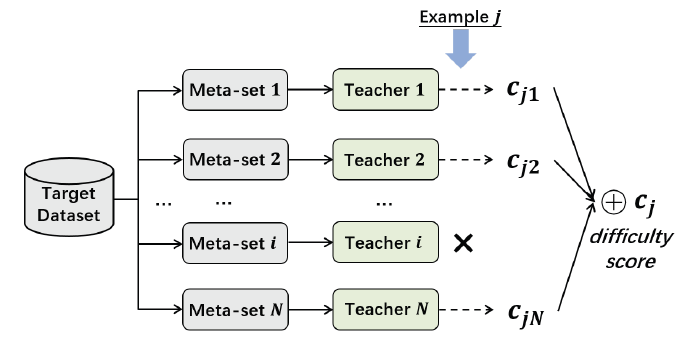
커리큘럼 러닝 난이도 측정 방법(GoldenMetric_F1)
1. 데이터셋을 N개로 나누고, 모델(teacher)도 N개를 준비한다.
2. 각 데이터셋에 대해 모델이 각각 학습해서 Inference N개가 나오게 된다. (N개의 데이터셋, 모델, Inference가 나옴)
3. 이렇게 나온 N개의 Inference를 가지고 Cross Review로 loss 계산을 수행한다.
- 예를 들어 데이터셋이 1~N으로 나눠졌다면, 1번 데이터셋에 대해 1번을 제외한 N-1개의 모델에서 1번 데이터셋에 대해 eval을 수행하고, 1번 데이터에 대한 Inference를 이용해 Loss계산을 합니다.
- 이렇게 나온 loss들을 합해서 1번 데이터셋에 대한 난이도 점수를 구합니다.
배열 알고리듬과 관련해서는 앞서 나온 난이도별 데이터들을 통해 각 단계에서 어려운 예제의 비율은 0에서 시작하여 원래 데이터 집합 분포에서 차지하는 비율이 어느 정도 도달할 때까지 점차 증가하는 방법으로 학습을 한다고 한다. 이 배열 알고리듬을 어닐링(Annealing)이라고 하며, 해당 방법은 다중 학습 단계를 통해 부드러운 전환을 제공한다.(사실 배열 알고리듬 부분은 잘 이해가 안 간다...)
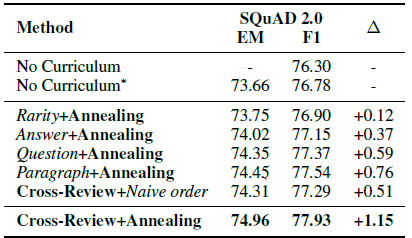
아무튼 이런 방식으로 학습을 진행했을 때 성능 향상이 있었다고 얘기를 하는데, 우리가 적용시킬 수 있을만한 QA Task인 SQuAD 2.0 데이터를 대상으로 한 실험에서도 커리큘럼 적용 전보다 F1 Score와 EM에서 성능 향상이 있었다. 따라서 우리 Reader 모델에 적용시켰을 때 성능향상을 기대할 수 있을 것 같다.
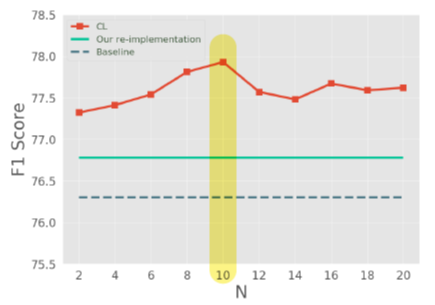
+) 추가적으로 해당 논문에서는 각 실험에 대한 파라미터 세팅값에 대해서도 언급하고 있으며, 난이도를 나누는데 있어서 데이터셋을 얼마로 나누는 게 가장 적합할 지에 대해서도 실험결과를 적어뒀다. SQuAD 2.0 데이터 대상으로 N이 10일 때 성능이 가장 좋았다. 추가적으로 N이 100으로 넘어가면 성능이 더 떨어진다고 하는데, 좀 더 관심이 있다면 논문을 찾아보는 게 훨씬 좋아보인다.
▶ Review (생각)
오늘은 가정사로 인해서 정말 정신이 없는 하루였다. 그러다보니 오전과 피어세션 전까지 제대로 프로젝트를 진행하지 못해 팀원분들께 죄송했다. 아무튼 오후와 저녁 동안 커리큘럼 러닝 관련해서 정보를 찾고 적용시킬 수 있을만한 부분에 대해서도 찾아봤는데 자료가 충분하지 않았었다. 논문을 읽긴 했는데, 연관된 코드도 없고 이를 자동화해서 구현시키려고 하면 시간이 너무 오래 걸릴 것 같았다. 따라서 멘토님께 여쭤봤는데, 자동화 부분을 빼고 데이터를 Split해서 넣어주는 방식을 사용하면 어떻겠냐고 말씀을 해주셨다. 확실히 데이터를 수동으로 나눠서 넣어준다면 해결할 수 있겠다는 생각이 들었다. 내일부터는 해당 부분을 구현해서 한 번 해봐야겠다.
내일은 주말에 정리하지 못했던 Git 강의를 보충해서 듣고 해당 내용도 포스팅에 정리할 계획이다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 79 (Lelvel2_MRC_9) (0) | 2022.05.12 |
|---|---|
| [일일리포트] Day 78 (Lelvel2_MRC_8) (0) | 2022.05.11 |
| [일일리포트] Day 76 (Lelvel2_MRC_6) (0) | 2022.05.09 |
| [16주차] 개인회고 (MRC Week2) (0) | 2022.05.06 |
| [일일리포트] Day 75 (Git특강2) (0) | 2022.05.06 |



