

이번 설 연휴동안 Deepseek-R1 모델이 매우 큰 신드롬을 일으키면서, 저 또한 해당 모델을 사용해보고자 하는 마음이 생겼습니다. 그래서 이번에 runpod에 Deepseek모델을 vLLM으로 올려보면서 겸사겸사 해당 방법을 정리해서 공유해보고자 합니다.(해당 글은 빠르게 나만의 모델을 올려보고자 하는 독자를 대상으로 작성했습니다. deepseek-R1 모델에 대한 설명이나 runpod, vLLM에 대한 설명을 다루고 있지 않습니다.)
Runpod Deploy
RunPod는 인공지능(AI) 및 머신러닝 애플리케이션을 위한 클라우드 컴퓨팅 플랫폼으로, 개인이나 작은 프로젝트 팀에서 GPU를 사용할 수 있게 해주는 서비스입니다. Runpod를 사용하기 위해서는 우선 Runpod에 들어가서 Pod를 deploy해야 합니다. Runpod 실행방법은 다음 글을 참고하시기 바랍니다.
이번에는 32B모델을 올려보고자 하기에, VRAM이 80GB인 H100 GPU를 선택했습니다.(1.5B 모델을 올리실 분들은 T4로도 충분합니다) LLM 모델을 올리기 위해서는 전 몇 가지 설정해야 하는 부분이 있습니다.

우선, 상단에 Community Cloud를 누르고, Internet Speed를 'Extreme'으로 설정해주셔야 합니다. 작은 모델은 괜찮지만, 32B모델은 실제 80GB이상의 모델 weiths 파일을 다운로드 받아야하기 때문에 네트워크 속도가 중요합니다. (실제 이를 고려하지 않으면, 모델 다운로드에만 2시간이 소요되기도 하며, 그만큼 GPU 사용 비용이 나가게 되는데...저도 알고 싶지 않았습니다)

다음으로, 모델을 선택하고 'Edit Template'을 눌러서, Expose HTTP Ports에서 8000번을 추가설정해주셔야 합니다. 이는 vLLM을 통해 모델을 올릴 때, 이 모델과 통신하기 위한 port번호입니다. (만약 추후 모델을 올릴 때, 서버의 port 번호를 변경하신다면 이 또한 같이 변경해주셔야 합니다)
추가적으로, Container의 Size도 다운받고자 하는 모델의 weights 크기만큼 확보를 해주셔야 하며, 실제 model weights 파일을 다운로드하기 위해 필요한 디스크 용량입니다. 필요한 모델의 weights 크기는 Huggingface Hub에서 확인해보실 수 있으며, 이번에는 100GB로 설정했습니다.
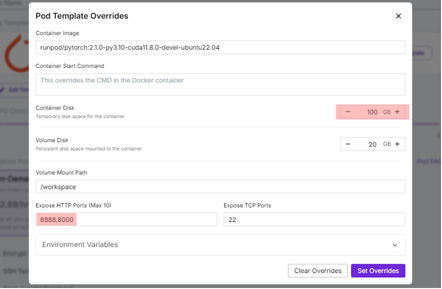
이렇게 설정을 완료하고, 'Deploy On-Demand'를 통해 올리면, 다음과 같은 화면을 잠시 기다리면 Pod가 생성됩니다.
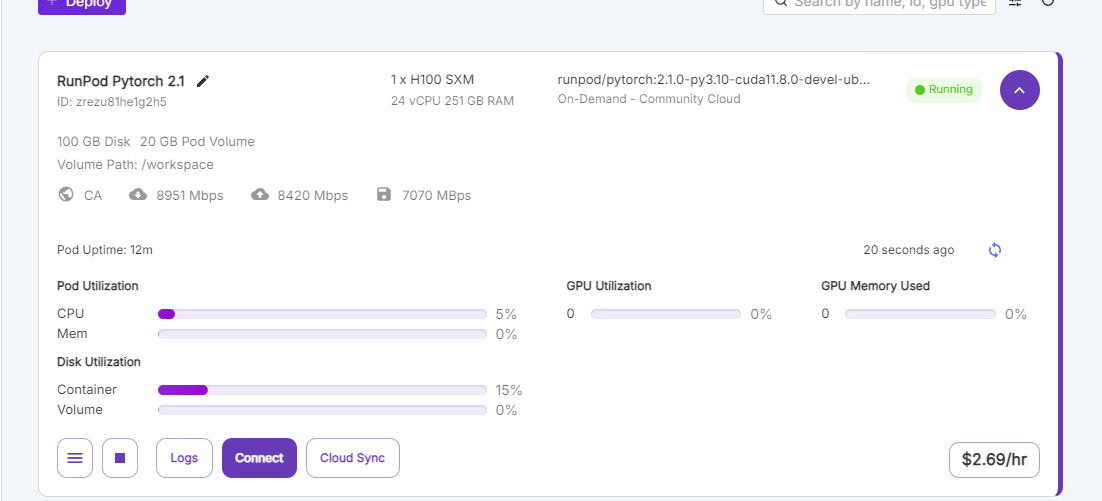
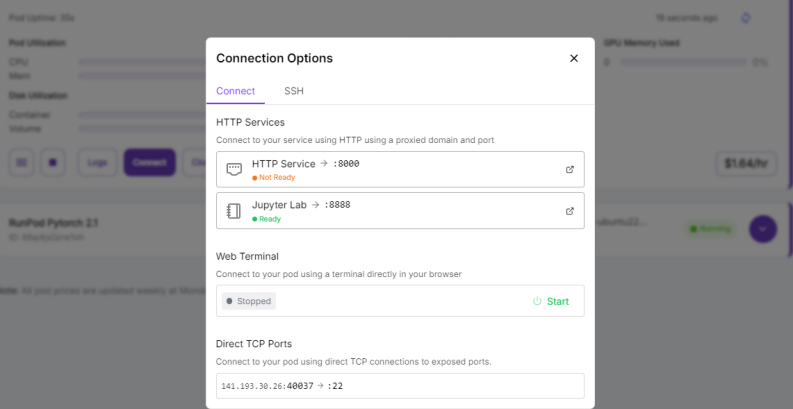
이제 이렇게 올린 Pod에서 코드 실행을 위한 주피터 노트북을 실행해보겠습니다. Connect를 누르면, 다음과 같이 Connection Options가 뜨게 됩니다. 이후 JupyterLab을 클릭하셔서 해당 서버에서 패키지 설치 및 코드 실행을 할 수 있습니다. (여기서 나오는 8000번 포트는 추후 저희가 모델을 올리면 활성화가 될 것이기에, Not Ready로 나타나게 됩니다)
vLLM으로 deepseek-R1 모델 서빙하기
이하 내용부터는 Terminal과 Jupyter Notebook의 경우 사용을 하실 수 있으시다고 전제하고, 코드 위주로 설명을 진행하겠습니다.
vLLM으로 모델을 서빙하는 것은 사실 크게 어렵지 않습니다. vLLM 자체에서 FastAPI 기반으로 serving을 지원하기 때문에 코드 몇 줄로 모델을 올려볼 수 있습니다. Terminal 창을 열어서 vLLM 패키지를 설치해줍니다.
pip install vllm
이후 다음 코드를 실행해서 모델 서빙을 진행합니다.사실 vLLM을 사용하면, deepseek모델뿐만 아니라 다른 모델들도 빠르게 서빙해서 사용해볼 수 있습니다.
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 1 --max-model-len 32768코드를 실행하면 다음과 같이 모델 파일을 다운로드 받기 시작합니다. 여기서 보시면 8GB씩이나 되는 파일들을 병렬로 다운로드 받고 있는데, 만약 네트워크 속도가 느리면 정말 암담해지기 때문에 네트워크 설정을 고려하셔야 합니다.

모델이 올라가고 나면 Localhost:8000 URL 주소가 활성화됐다고 나오게 됩니다. 해당 주소는 당연히 접근이 안 되시는데, 현재 이렇게 올린 모델의 localhost는 저희 컴퓨터의 localhost와 주소가 다르기 때문입니다. 그래서 조금 전에 'Not Ready' 상태였던 HTTP Service를 다시 보시면, 이제는 ready상태가 된 것을 확인하실 수 있습니다.

해당 링크를 클릭하셔서 서버에 접근해보실 수 있습니다. 해당 링크를 클릭하시면 'page not found'메시지가 뜰 겁니다만, 당황하지 마시고 주소창 뒤에 `/docs`를 붙여주시면 됩니다. 그러면 다음과 같이 FastAPI가 지원하는 Swagger 페이지를 확인하실 수 있습니다.
https://zrezu81he1g2h5-8000.proxy.runpod.net/docs
# /docs 이하 주소는 개인마다 다릅니다

로컬에서 deepseek-R1 모델 호출하기
이제 RunPod로 올린 모델을 로컬에서 실행해보도록 하겠습니다. requests 라이브러리를 활용해 다음과 같이 간단한 메시지를 요청하는 함수를 만들고 메시지를 요청해보도록 하겠습니다.
runpod_vllm_url = 'https://zrezu81he1g2h5-8000.proxy.runpod.net' # 개인 서버 호스트 주소로 변경해주시면 됩니다.
post_url = f'{runpod_vllm_url}/v1/chat/completions' # chat/completions 뿐만 아니라 comletions나 generation도 사용 가능합니다.
def get_response(model, question):
# 호스트는 변경 가능합니다.
headers = {"Content-Type": "application/json"}
data = {
"model": model,
"prompt": "you are a helpful assistant",
"messages": [{"role": "user", "content": question}],
"temperature": 0.0,
}
response = requests.post(post_url, headers=headers, data=json.dumps(data))
return response.json()['choices'][0]['message']['content']이렇게 생성한 함수를 호출해보면, 다음과 같이 질문에 대한 답변이 나오는 것을 확인할 수 있습니다. 간단한 내용에 대해서 질문을 한 번 해보겠습니다.
model= 'deepseek-ai/DeepSeek-R1-Distill-Qwen-32B'
question = '한국말을 할 줄 알아?'
get_response(model, question)
# '<think>\n\n</think>\n\n네, 한국말을 할 줄 압니다! 도와드릴까요? 😊'model= 'deepseek-ai/DeepSeek-R1-Distill-Qwen-32B'
question = 'deepseek r1에 대해 한국어로 간단하게 설명해줘'
get_response(model, question)
"""
<think>
Okay, so I need to explain DeepSeek-R1 in Korean. Let me start by recalling what I know about DeepSeek-R1. It's an AI assistant created by DeepSeek, right? I think it's designed to help with various tasks, maybe like answering questions, providing information, or assisting with research.
I should mention that it's an advanced AI, probably using some form of deep learning or large language models. It might be capable of handling multiple languages, including Korean, which is important for the explanation.
... <중략>...
I should avoid any markdown or formatting as per the instructions and keep the explanation straightforward.
I think that's a solid approach. Now, I'll translate these points into a concise Korean explanation.
</think>
DeepSeek-R1는 딥시크(DeepSeek)가 개발한 인공지능(AI) 어시스턴트입니다.
이 AI는 다양한 작업을 돕기 위해 고급 AI 기술을 활용하며, 자연어 처리(Natural Language Processing)를 통해
인간과 유사한 언어로 대화하고 정보를 제공할 수 있습니다.
DeepSeek-R1는 질문에 답변하거나, 정보 검색을 도와주며,
고객 서비스, 콘텐츠 생성, 교육 등 여러 분야에서 활용될 수 있습니다.
"""
RunPod 종료하기
RunPod와 같은 클라우드 서비스의 장점은 사용한 만큼만 비용을 지불한다는 것이고, 단점 또한 사용한 만큼 비용이 나가는 것입니다. 그렇기 때문에 종료도 매우 중요한 작업입니다. 종료는 어렵지 않고, 하단에 Stop 🔲버튼을 클릭해주시면 됩니다.
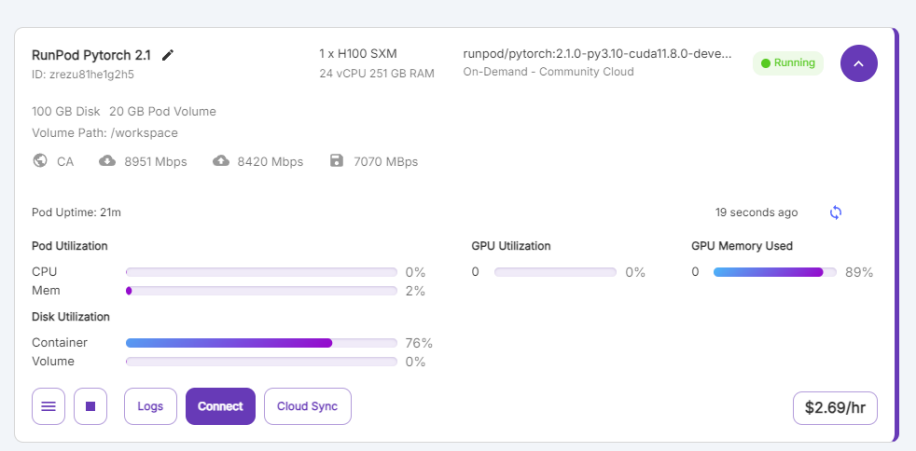
다음과 같이 메시지가 뜨면, Stop Pod를 눌러주시면 됩니다. Pod를 종료하게 되면, /workspace 경로의 저장된 데이터 이외에는 다 제거가 된다는 의미입니다. 그리고 해당 데이터를 보관하기 위해서 disk용량이 얼마만큼 부과된다는 의미입니다.
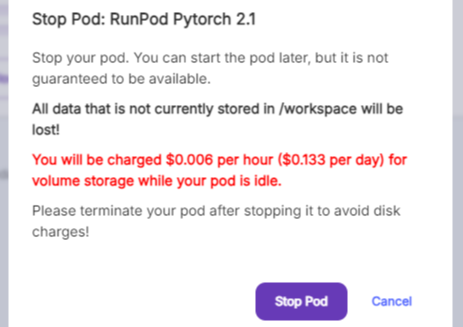
만약, 빠른 시일 내에 해당 Pod를 다시 띄울 일이 없으시다면, 휴지통🗑️ 버튼을 클릭하셔서 Pod 자체를 'Terminate' 해주셔야 합니다. 그렇지 않으면 디스크 사용량에 대해서 계속해서 요금이 부과되게 됩니다.
마치며
DeepSeek-R1이 OpenAI의 유료모델들과 비교해 뛰어난 성능을 보인다면서 많은 이슈가 있어서, 저 또한 눈길이 갔습니다. 해당 모델에 대해서는 많은 설명이 나와있지만, 아직까지 모델을 사용하기 위한 방법을 알려주는 자료는 조금 부족한 것 같아서 작성을 해봤습니다. 사실 저 또한 머신러닝 엔지니어로 일하면서, 퇴근하고서는 GPU 자원이 부족해서 LLM을 돌려보지 못했던 상황이 있었습니다. 그런 점에서 조금은 가볍게 모델을 돌려보고 싶으신 분들에게 runpod와 vllm serve는 좋은 선택지가 될 것 같다고 생각합니다.
추가적으로 DeepSeek-R1 모델의 경우 32B이지만, <think>과정을 통해서 답변을 내기까지 사고하는 과정을 추가적으로 제시해준다는 점이 인상깊었습니다. 유료 API를 통해서 접근할 수 있었던 해당 모델들이 오픈소스로 풀리고, 그만큼 저렴한 비용으로 사용할 수 있게 된다는 점에서도 고무적인 것 같습니다. 추후 한국어로 Finetuning 된 모델들이 나온다면, 해당 모델들을 가지고 더 다뤄봐도 좋을 것 같습니다.
'기술 견문록 > MLOps' 카테고리의 다른 글
| [MLFlow] MLFlow의 LLMOps-2 (LLMOps 기능 알아보기) (1) | 2025.08.28 |
|---|---|
| [MLFlow] MLFlow의 LLMOps-1 (MLFlow와 LLMOps에 대해) (1) | 2025.08.28 |
| [OpenSearch] OpenSearch를 알아보자 (1) | 2025.01.04 |
| [RunPod] RunPod (비용 및 Pycharm SSH 연결 방법) (0) | 2024.11.24 |
| [FastAPI] FastAPI를 쉽게 알아보자 (FastAPI 시식 코너) (4) | 2024.11.08 |