
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 백준
- 프로그래머스
- 구현
- dp
- 부스트캠프_AITech3기
- 그리디
- 개인회고
- 부스트캠프_AITech_3기
- 그래프이론
- 이코테
- 기술면접
- 파이썬 3
- 백트랙킹
- 이진탐색
- 주간회고
- dfs
- Level1
- 알고리즘_스터디
- Level2
- 단계별문제풀이
- 정렬
- 다시보기
- mrc
- ODQA
- 알고리즘스터디
- 글또
- python3
- Level2_PStage
- U_stage
- 최단경로
- Today
- Total
국문과 유목민
[일일리포트] Day 11 (Matplotlib) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
Data Visualization Base
데이터 시각화는 데이터를 그래픽 요소로 매핑해서 시각적으로 표현하는 것을 의미한다. 시각화의 요소로는 목적, 독자, 데이터, 스토리, 방법, 디자인이 있다. 데이터 시각화를 위해서는 당연히 데이터가 필요한데, 데이터셋의 종류로는 정형 데이터, 시계열 데이터, 지리 데이터, 네트워크 데이터, 계층적 데이터, 비정형 데이터가 있다.
- 정형데이터: 테이블 형태로 제공되는 데이터로, 가장 쉽게 시각화할 수 있는 데이터 셋으로 통계적 특성이나 feature, 데이터 간 관계를 비교 확인하는데 사용한다.
- 시계열데이터: 시간 흐름에 따른 데이터로 Time-Series Data라고도 한다. 기온, 주가 등의 정형 데이터와 음성, 비디오와 같은 비정형 데이터가 존재한다. 시간 흐름에 따른 추세, 게절성, 주기성 등을 살핀다.
- 지리(지도) 데이터: 지도 정보와 보고자 하는 정보 간의 조화가 중요한 데이터이며 길, 경로, 분포 등 다양하게 사용되고 있다.
- 관계 데이터: 객체와 객체 간의 관계를 시각화하는 것으로 객체는 Node로 관계는 Link로 표현한다. Graph나 Netwoak 형태로 나타낼 수 있다.
- 계층적 데이터: 관계 데이터 중에서 포함관계가 분명한 데이터이며 네트워크 시각화로 표현이 가능하다. Tree, Treemap, Sunburst 등이 대표적이라고 할 수 있다.
- 데이터의 종류
데이터의 종류는 다양하게 분류가 가능하지만 대표적으로 4가지로 분류가 가능하다.
- 수치형 (비례, 비율로 표현 가능한 데이터)
- 연속형: 길이, 무게, 온도 등 (소수점까지 나올 수 있는 데이터)
- 이산형: 주사위 눈금, 사람 수, 횟수 등 (정수형으로 나올 수 있는 데이터)
- 범주형
- 명목형: 혈액형, 종교, MBTI 등
- 순서형: 학년, 별점, 등급 등
- 시각화 이해하기
mark: 점, 선, 면으로 이루어진 데이터 시각화 요소
channel: 각 마크를 변경할 수 있는 요소들 (위치, 색, 모양, 크기, 부피, 기울기)
전주의적 속성: 주의를 주지 않아도 인지하게 되는 요소를 말한다. 동시에 여러가지 channel을 사용하면 인지가 어렵기 때문에 이를 적절하게 사용해야 한다. 그렇게 하면 시각적 분리 효과(visual pop-out)를 통해 정보를 효과적으로 전달할 수 있다.
Matplotlib
'Matplotlib'은 파이썬에서 사용할 수 있는 시각화 라이브러리로 numpy와 scipy 등을 베이스로 하여 다양한 라이브러리와 호환성이 좋다. 또한 다양한 시각화 방법론을 제공하고 다른 시각화 라이브러리보다 범용성이 넓기 때문에 제일 base가 되는 라이브러리이다.
- 기본 Plot (Figure와 Plot)
Matplotlib에서 그리는 시각화는 Figure라는 큰 틀에 Ax라는 서브플롯을 추가해서 만드는데, Figure는 큰 틀이라 서브플롯을 최소 1개 이상 추가해야 한다.
다음 코드는 figure 객체를 선언하고 Ax라는 서브플롯을 추가하는 코드이다. 이렇게 만든 서브플롯에 그리고자 하는 데이터 값을 넣어줘서 사용을 할 수 있다.
fig = plt.figure(figsize=(12, 7))
# fig.set_facecolor('orange')
x1 = [1, 2, 3]
x2 = [3, 2, 1]
ax1 = fig.add_subplot(121) # (1,2) 로 쪼개고 1번
plt.plot(x1)
ax2 = fig.add_subplot(122) # (1,2) 로 쪼개고 2번
plt.plot(x2)
plt.show()하지만 위처럼 할 필요없이 바로 서브플롯 객체 ax에 데이터를 넣어서 그릴 수 있는데, 보편적으로는 위의 방법보다 아래 방법을 더 많이 사용한다.
fig = plt.figure()
x1 = [1, 2, 3]
x2 = [3, 2, 1]
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212)
ax1.plot(x1)
ax2.plot(x2)
plt.show()- Plot의 요소들
Matplotlib에는 그래프를 그릴 때 사용할 수 있는 여러가지 요소들이 존재한다. 우선, 한 서브플롯에서 여러 개를 그릴 수 있기도 하며, 색상을 지정할 수도 있고, 텍스트를 사용할 수도 있다. 또한 legend(범례)나 title(제목), xticks(x축값), yticks(y축값), ticklabels(축 이름) 등을 사용할 수 있습니다.
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot([1, 1, 1], label='1')
ax.plot([2, 2, 2], label='2')
ax.plot([3, 3, 3], label='3')
ax.set_title('Basic Plot')
ax.set_xticks([0, 1, 2])
ax.set_xticklabels(['zero', 'one', 'two'])
ax.text(x=1, y=2, s='This is Text') # (x, y) 위치에 text 추가
# ax.annotate(text='This is Annotate', xy=(1, 2))
ax.legend()
plt.show()
Barplot
BarPlot이란 직사각형 막대를 사용해 데이터의 값을 표현하는 차트이며 그래프이다. 범주형(Categorical)에 따른 수치값을 비교하기에 적합한 방법이다. Barplot을 활용해서 여러 group을 보여줄 수 있기도 한데, 플롯을 여러 개 그리는 방법도 있고, 한 개의 플롯에 동시에 나타내는 방법이 있다. 다음은 한 개의 플롯에 동시에 나타내는 방법의 종류이다.
- Stacked Bar Plot: 2개 이상의 그룹을 쌓아서 표현하는 bar plot, 비율 정보를 보기에 유리하다. (Percentage Stacked Bar Chart)로 만들어서 활용한다.
- Overlapped Bar Plot: 2개 그룹만 비교한다면 겹쳐서 만드는 것도 하나의 선택지가 될 수 있다. 같은 축을 사용하기 때문에 비교가 쉽다.
- Grouped Bar Plot(제일 추천): 그룹별 범주에 따른 bar를 이웃되게 배치하는 방법. 단, Matplotlib에서 구현이 비교적 까다롭기 때문에 seaborn으로 사용하면 좋다.
다음과 같은 방법들은 그리고자 하는 그룹이 5개 ~ 7개이하일 때 효과적이다. 따라서 그룹이 많다면 데이터가 적은 그룹은 ETC로 묶어서 그릴 수 있다.
- 정확한 BarPlot 그리기 위한 지침
- 실제 값과 그에 표현되는 그래픽으로 표현되는 잉크 양은 비례해야 한다.
- 반드시 x축의 시작은 zero여야 한다. 만약 차이를 나타내고 싶다면 plot의 세로 비율을 늘려서 차이를 나타낼 수 있다.
- 더 정확한 정보를 전달하기 위해서는 정렬이 필요하다. (sort_values(), sort_index()) 단, 데이터의 종류에 따라 정렬방법도 달라지게 된다. 시계열 데이터의 경우 시간순, 수치형 데이터의 경우 크기순, 순서형 데이터의 경우 범주의 순서, 명목형 데이터의 경우 범주의 크기에 따라 정렬해야 한다.
- 여백을 통해 공간활용만 적절하게 조정해도 가독성이 높아진다.
- 직사각형이 아닌 다른 형태의 bar를 사용하거나 3D그래프를 그리는 등 필요없는 복잡함은 지양해야 한다. 하지만 축이나 Grid, ticklabels, text, uncertainty등의 정보는 필요에 따라 추가하기도 한다.
# 간단한 bar plot 예제
group_cnt = student['race/ethnicity'].value_counts().sort_index()
fig = plt.figure(figsize=(15, 7))
ax_basic = fig.add_subplot(1, 2, 1)
ax = fig.add_subplot(1, 2, 2)
ax_basic.bar(group_cnt.index, group_cnt)
ax.bar(group_cnt.index, group_cnt,
width=0.7, # 두께 조절
edgecolor='black', # 테두리
linewidth=2, # 테두리 두께
color='royalblue' # 색변경
)
ax.margins(0.1, 0.1) # 그래프 공백
for s in ['top', 'right']:# axes 선 제거
ax.spines[s].set_visible(False)
plt.show()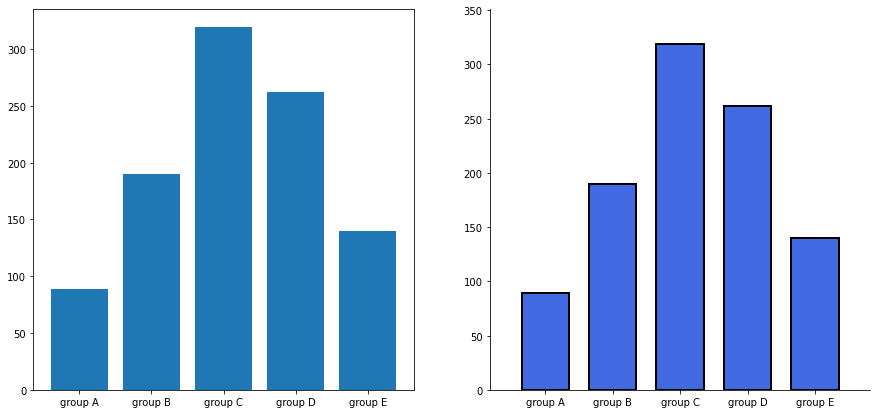
Lineplot
연속적으로 변화하는 값을 순서대로 점으로 나타내고, 점들을 선으로 연결한 그래프이다. 시간/순서에 대한 변화(시계열 분석)에 적합하여 추세를 살피기 위해 사용한다. 한 그래프 안에 5개 이하의 선을 사용하는 것을 추천하며, LinePlot의 요소로는 color, marker, markersize, linestyle, linewidth 등이 있다. LinePlot을 시계열 데이터에 사용할 때 noise가 발생하는데, 해당 noise로 인한 인지적인 방해를 줄이기 위해 smoothing 기법을 사용한다.
- 정확한 LinePlot 그리기 위한 지침
추세: LinePlot은 Bar plot과 다르게 꼭 축을 0에 둘 필요없이 추세를 보기위한 목적으로 사용할 수 있다. 너무 구체적으로 grid, marker 등을 제시된 line plot보다는 어느정도 생략된 lineplot이 더 흐름을 보기에는 좋다.
간격: 규칙적인 간격이 아니라면 오해를 줄 수 있다. 그래프 상에서 규칙적일 때 기울기 정보의 오해를 줄 수 있고, 그래프 상에서 간격이 다를 때 없는 데이터를 있다고 오해할 수 있다. 따라서 규칙적인 간격의 데이터가 아니라면 각 관측 값에 점으로 표시해서 오해를 줄이자.
보간: Line은 점을 이어 만드는 요소. 점과 점 사사이에 데이터가 없어 이를 잇는 방법을 보간이라고 한다. 스무딩 방법이기 때문에, Presentation에는 좋은 방법일 수 있다. 하지만 일반적인 분석에서는 곡선 보간은 최대한 지양해야 하는데, 없는 데이터를 있다고 생각할 수 있고, 작은 차이도 사라지게 된다
이중 축 사용: 한 plot에 대해 2개의 축을 이중 축(dual axis)이라고 한다. 같은 시간 축에 대해 서로 다른 종류의 데이터 표현, 한 데이터에 대해 단위가 다른 경우를 표현할 때 사용한다. 하지만 이중 축을 사용하는 것보다는 2개의 plot을 그리는 것이 훨씬 낫다.
Tip!
- 범례 대신에 라인 끝 단에 레이블을 추가하면 식별에 훨씬 도움이 된다.
- Min/Max 정보(또는 원하는 포인트)는 추가해주면 도움이 될 수 있다. (annotation)
- 보다 연한 색 혹은 보색을 사용해 uncertainty표현 가능하다. (신뢰구간, 분산, Min/Max 값 등)
fig = plt.figure(figsize=(7, 7))
np.random.seed(97)
x = np.arange(20)
y = np.random.rand(20)
ax = fig.add_subplot(111)
ax.plot(x, y,color='lightgray', linewidth=2,)
ax.set_xlim(-1, 21)
# max 선
ax.plot([-1, x[np.argmax(y)]], [np.max(y)]*2,linestyle='--', color='tomato')
ax.scatter(x[np.argmax(y)], np.max(y), c='tomato',s=50, zorder=20)
# min 선
ax.plot([-1, x[np.argmin(y)]], [np.min(y)]*2,linestyle='--', color='royalblue')
ax.scatter(x[np.argmin(y)], np.min(y), c='royalblue',s=50, zorder=20)
plt.show()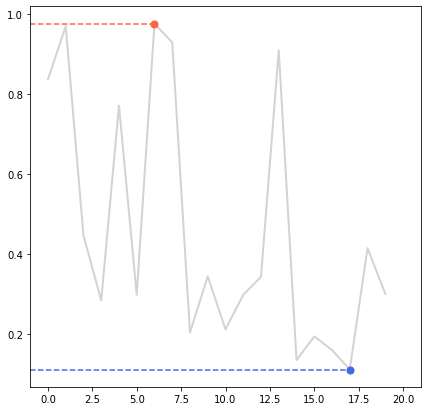
Scatterplot
점을 사용하여 두 feature 간의 관계를 알기 위해 사용하는 그래프이다. 점에서 다양한 variation 사용이 가능하다(color, marker, size). 상관 관계 확인(양의 상관관계 / 음의 상관관계 / 없음)을 확인할 수 있으며, 군집이나 값 사이의 차이를 보거나 이상치를 확인하는데 사용하기도 한다.
- OverPlotting
점이 많아질수록 점의 분포를 파악하기 힘들기 때문에 이를 지원하기 위해 조절할 수 있는 것들이 있다.
- 투명도 조정
- 지터링(jittering): 점의 위치를 약간씩 변경
- 2차원 히스토그램: 히트맵을 사용해 깔끔한 시각화
- Contour plot: 분포를 등고선을 사용하여 표현
- 점의 요소와 인지
- 색 (color): 연속은 gradient, 이산은 개별 색상으로 표현한다. 가장 많이 사용하는 방법
- 마커(marker): 거의 구별하기 힘들고, 크기가 고르지 않기에 마커 자체만 사용하지 않는다.
- 크기(size): 흔히 버블 차트라고 부르며 구별하기는 쉽다는 장점이 있지만 오용하기도 쉽다는 단점도 있다. 따라서 관계 비교보다는 각 점간 비율이나 크기에 초점을 둬야할 때 사용한다.
- Tip!
- 인과관계와 상관관계는 다르다. 인과관계를 도출하기 위해서는 도매인 정보와 같은 사전정보와 함께 가정으로 제시되어야 한다.
- 추세선을 사용하면 scatter의 패턴을 유추할 수 있지만, 2개 이상이 되면 가독성이 떨어지므로 1개만 사용해서 분포를 확인할 때 사용한다.
- ScatterPlot에서의 Grid사용은 지양해야 하지만, 해야할 경우에는 색은 무채색으로 하거나 최소한으로 한다.
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
markers = ['>','o','*']
colors = ['b', 'y', 'r']
for idx, species in enumerate(iris['Species'].unique()): # 각 종의 이름을 받아옴
iris_sub = iris[iris['Species']==species]
ax.scatter(x=iris_sub['SepalLengthCm'],
y=iris_sub['SepalWidthCm'],
label=species,
marker = markers[idx],
color = colors[idx]
)
ax.legend()
plt.show()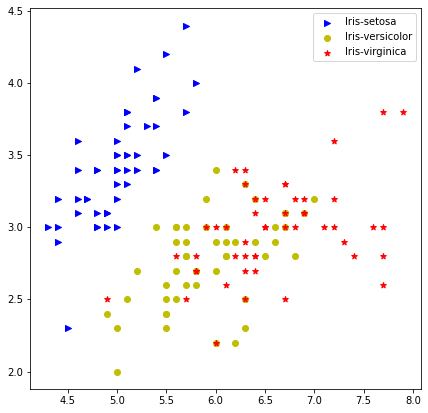
▶ Review (생각)
오랜 연휴를 끝내고 다시 부스트 캠프로 돌아오게 됐다. 사실 오늘 오랜만에 공부를 하려고 하니 갑자기 머리가 아파서 명절 후유증인가 생각이 들었었는데 그래도 오늘 생각했던 분량은 끝내서 다행이다.
이번주는 데이터 시각화 강의로 MatPlotlib과 Seaborn라이브러리를 배우게 됐는데 마스터분의 강의가 깔끔했고 딱 필요한 것만 짚고 넘어가는 느낌이라 이해하기 쉬웠다. 물론 지금까지 배웠던 지식들이 쌓여서 그런지 훨씬 수월하게 배웠던 것도 없지는 않았겠지만, 실제 잘 사용하지 않는 그래프 대신에 자주 사용하는 기법들과 기술들을 알려주는 느낌이 들어서 흥미를 가지고 공부할 수 있었다.
정리를 하면서 마지막 실습 코드만 변형해서 일부만 작성했다. 그래서 나중에 필요할 때 다시 꺼내서 보면 좋을 것 같다. Matplot을 활용한 데이터 시각화를 실제로 학습을 진행하면서 얼마나 사용하게 될지는 모르겠지만, 혹 더 많이 사용하게 된다면 이번주에 배운 내용을 가지고 별도로 정리해두는 것도 좋을 것 같다.
내일은 남은 강의를 다 듣고서 피어세션에서 조원들과 같이 하기로 한 탬플릿 Annotation 작업을 진행하고, 추가적으로 개인 공부를 더 하면 좋을 것 같다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [3주차] 학습 정리 및 회고 (0) | 2022.02.04 |
|---|---|
| [일일리포트] Day 12 (Matplotlib2) (0) | 2022.02.04 |
| [2주차] 학습 정리 및 회고 (1) | 2022.01.28 |
| [일일리포트] Day 10 (0) | 2022.01.28 |
| [일일리포트] Day 09 (0) | 2022.01.26 |



