
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 기술면접
- Level1
- 주간회고
- dp
- 알고리즘_스터디
- 최단경로
- 개인회고
- 단계별문제풀이
- Level2
- 프로그래머스
- 부스트캠프_AITech3기
- 부스트캠프_AITech_3기
- 백트랙킹
- 정렬
- 다시보기
- 글또
- 이진탐색
- mrc
- 구현
- python3
- ODQA
- dfs
- 이코테
- 그래프이론
- 파이썬 3
- 백준
- Level2_PStage
- 그리디
- 알고리즘스터디
- U_stage
- Today
- Total
국문과 유목민
[일일리포트] Day 14 (RNN 계열) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
RNN
Sequential data는 몇 개의 입력이 들어올 지 모르기 때문에 CNN을 사용할 수 없다. Naive Sequence Model을 활용하게 되면, 과거에 내가 고려해야 하는 정보가 계속 늘어나게 된다. 따라서 이러한 문제를 해결할 수 있는 방법은 과거의 볼 데이터를 한정해 놓는 것이다. 이러한 모델을 Autoregressive model(자기회귀 모델)이라고 한다.
MarkovModel
First-order autoregressive model이라고 하며, 현재 바로 전의 과거에만 dependent하다는 의미이다. 하지만 현실적으로 말이 안되는 모델이다.
$$\prod_{t=1}^T p(x_t | x_{t-1})$$
Latent Autoregressive Model
Input과 output 사이에 Hidden state가 있어 이전 정보를 Summarize해서 현재에 전해주는 방법이다.
그리고 이러한 방법들을 가장 쉽게 설명할 수 있는 방법이 바로 Recurrent Neural Network, RNN이다. RNN은 아래와 같은 구조를 가진다.

하지만 RNN은 Short-term dependency라는 단점이 존재하기 때문에 몇 step 전의 정보는 고려할 수 있지만 정보가 길어질 경우 힘들어진다. 이러한 현상은 Weight를 계속 곱하기 때문에 Vanishing(Elpoding) Gradient가 발생해서 사용에 어려움이 생기는 Long Term Dependency가 발생한다. 그리고 이러한 문제를 보완하기 위해 나온게 바로 LSTM이다.
LSTM
Long Term Dependency를 해결하기 위해 생긴 방법이다. LSTM의 core idea는 cell state인데, cell state는 컨베이어 벨트라고 생각하면 된다. 여기서 gate는 input이 들어올지 말지를 결정하는 요소이다. gate는 총 3가지가 존재한다.
- $X_t$: input
- $h_t$: output(hidden state)
- cell state: cell state는 지금까지의 정보를 summarize한 정보라고 생각하면 된다.
- previous cell state → next cell state
- previous hidden state → next hidden state
LSTM을 보면 input은 총 3개이고, output도 3개이지만 실제적인 Output은 $h_t$1개이다. gate는 3개가 있는데, Forget gate, Input gate, Output gate가 그것이다.
- Forget gate: 어떤 정보를 버릴 지를 결정한다. $f_t$ 는 0과 1사이의 값을 가진다.
- Input gate: 어떤 정보를 올릴 지를 결정한다.
- $\tilde{C_t}$: 현재 정보와 이전 출력값을 가지고 만들어지는 cell state 후보군이다.
- update cell: $C_t=f_t*C{t-1}+i_i*\tilde{C_t}$
- Output gate: 어떤 값을 밖으로 내보낼지 결정한다.

참고) https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
GRU (Gated Recurrent Unit)
LSTM에서 조금 더 간소화된 방법이다. GRU에서는 cell state가 없고, hidden state만 있기 때문에 output gate가 필요없어졌다. 따라서 두 개의 gates(reset gate and update gate)만 가지고도 LSTM과 비슷한 역할을 기대할 수 있다. 그리고 똑같은 Task에서 LSTM보다 GRU가 더 좋은 성능을 보이는 경우가 많다. (하지만 요즘에는 Transformer를 더 많이 사용한다.)
Transformer
Sequence modeling을 함에 있어 Trimmed Sequence, Omitted Sequence, Permuted Sequence(?)와 같은 Sequence들이 생기는 문제가 생겼는데, 이러한 문제를 해결하기 위해 Transformer가 등장했다.
Trnasformer에 대한 내용을 정리하기 전에, 다음 블로그 (The Illustrated Transformer)를 살펴보면 Animation과 함께 설명이 잘 되어있어 살펴보기를 추천한다. (참고로 3개의 번역 글이 존재하는데 모두 잘 정리되어 있다고 생각한다) 정리는 간단한 부분만 진행하도록 하겠다.
Transformer는 문장(Sequential A)이 주어지면 다른 문장(Sequential B)으로 바꾸는 NMT(Neural machine translation) Task로 출발했다. 그렇기에 어떤 Task에 모델을 사용하느냐에 따라 입력과 출력의 도메인이나 단어 수가 다를 수 있다. 하지만 하나의 모델을 사용해서 해당 프로세스를 처리할 수 있다. Encoder 부분에서는 feature N개를 한번에 처리할 수 있는 구조로 되어 있다. Transformer에는 동일한 구조를 가지지만 네트워크 파라미터가 다르게 학습이 되는 Encoder와 decoder가 Stack되어 있다.
Encoder
인코더는 self attention → Feed Forward Neural Network 구조로 구성되어 있다.
- Self-attention: 트랜스포머가 잘 되는 이유라고 할 수 있다. 단어가 주어지면 각 단어에 대한 vector를 만들어준다. $x_1$을 $z_1$으로 바꿀 때, 다른 $x_2$, $x_3$ 등도 고려한다(이전 단어를 고려한다는 뜻).
- Feed-Foward Path: Word에 대해 서로 dependency가 없이 출력을 진행한다.

Self-attention을 살펴보면 다음과 같은 연산을 통해서 계산이 진행된다. Query, Key, Value Vector들은 하나의 단어마다 만들어지는데, 우리는 이러한 vector를 통해서 주어진 단어를 변화시킬 수 있다.

프로세스는 다음과 같다.
- 인코딩하고자 하는 단어의 query벡터와 나머지 단어들의 key벡터를 내적해서 score를 구한다.
- score에 루트를 씌운 $d_k$를 나눠준다. (여기서 $d_k$는 input dim의 차원이라고 볼 수 있다 여기서는 64였다)
- 앞선 score에 softmax를 취한다. (이렇게 나온 값은 scalar값이다)
- 최종적으로 사용할 값은 score와 value vector를 weighted sum한 값이다. 이 값은 처음 들어온 단어가 인코딩된 값이다.
사실 실제 연산에서는 이 과정이 행렬로 진행되게 된다. 따라서 다음과 같은 식을 가진다고 할 수 있다.
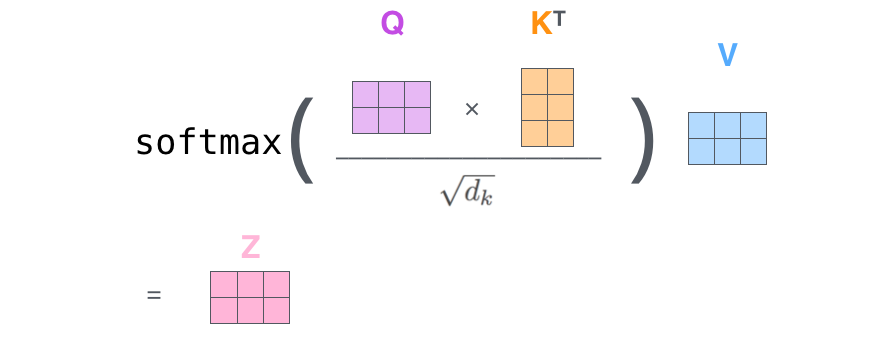
참고로 Query Vector와 Key Vector의 차원은 같아야 하지만, Value Vector의 차원은 달라도 된다. (하지만 편의상 차원을 같게하는 편)
- Transformer의 연산이 잘 될 수 있는 이유
입력이 고정되더라도 출력이 달라질 수 있는 여지가 있기에 훨씬 더 많은 것을 표현할 수 있다. 하지만 그만큼 많은 입력을 처리해야 하기에 많은 메모리를 차지한다는 단점이 있다.
MHA (Multi Head Attention)
위 Encoding과정에서 attention을 여러번 하는 것이다. Query, Key, Value를 여러 개 만든다는 뜻인데, 하나의 임베딩된 단어에서 여러 개의 인코딩된 벡터가 나오게 된다. 여기서 고려할 것인 임베딩된 단어의 차원과 인코딩 벡터의 차원을 맞춰야 한다는 것이다.
예를 들어 임베딩이 10차원이었다면 8개의 인코딩된 벡터가 나왔을 때, 80차원의 인코딩 벡터가 생성되게 된다. 그래서 우리는 이러한 80차원의 인코딩 벡터를 10차원으로 줄여서 차원을 맞춰줘야 한다. 하지만 코드 구현 시 일부가 달라지게 된다.
- Positioning Encoding이 필요한 이유
attention의 경우 order(순서)에 독립적이라는 특성을 가지고 있다. 단적인 예로 'I love DeepLearning' 문장의 순서를 바꿔도 attention은 눈치채지 못할 수 있다는 것이다. 따라서 Positional Encoding이 필요하다. Transformer 모델은 각각의 입력 embedding에 “positional encoding”이라고 불리는 하나의 벡터를 추가한다. 이 벡터들은 모델이 학습하는 특정한 패턴을 따르는데, 이러한 패턴은 모델이 각 단어의 위치와 시퀀스 내 다른 단어 와의 위치 차이에 대한 정보를 알 수 있게 해준다.

Decoder
- Transformer는 key(K)와 value(V)를 전달한다. output sequence에서는 autogressive하게 단어가 생성되게 된다.
- 학습할 때는 마스킹이라는 방법을 사용함으로써 미래의 정보를 활용하지 않게 한다.
- Decoder에 있는 Encoder-Decoder Attention layer는 MHA의 self-atention과 똑같이 동작한다.
- 마지막 레이어에서 디코더의 stack 출력을 convert함으로써 그러한 단어에서 매번 샘플링하는 방식으로 사용한다.
Decoder의 프로세스에 대해서는 정말 간단하게만 정리되어 있다. 더 쉽게 이해하고 싶다면 앞서 올린 참고 블로그를 확인하기 바란다.
▶ Review (생각)
이번 주 할당된 강의 중 남은 강의였던 RNN과 Generator에 대한 강의를 다 듣기는 했다. 그런데 Generator 강의를 아직 완전히 이해하지 못했고, 또 Transformer에 대한 이해를 할 겸 잘 정리해두면 좋을 것 같아서 오늘은 RNN과 Transformer에 대해서만 정리해봤다. 내일 Generator와 함께 'attention is all you need' 논문을 읽는다면 정리하도록 하겠다.
Transformer의 경우 attention의 등장 이후 특히 NLP 분야에서 아주 자주 사용되는 알고리즘이기에 확실히 짚고 넘어가면 좋을 것 같다는 생각에 조금 집중적으로 봤다(아직 부족하다). 강의를 보면서 이해하기 조금 어려웠던 부분을, 참고하라고 알려주신 블로그를 보면서 이해할 수 있었다. 해당 블로그에는 3개의 포스팅밖에 없는데, 한 흐름으로 되어있어서 다 읽어보니 전체적인 프로세스를 쉽게 이해할 수 있었다. 특히 마지막 3번째 포스팅의 경우 BERT와 ELMO에 대해서도 한글번역으로 설명해줘서 조금 더 쉽게 이해할 수 있었다. 따라서 해당 링크를 올려두도록 하겠다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 16 (0) | 2022.02.10 |
|---|---|
| [일일리포트] Day 15 (0) | 2022.02.09 |
| [일일리포트] Day 13 (DL Basics) (0) | 2022.02.07 |
| [3주차] 학습 정리 및 회고 (0) | 2022.02.04 |
| [일일리포트] Day 12 (Matplotlib2) (0) | 2022.02.04 |



