
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 정렬
- 그리디
- Level1
- 단계별문제풀이
- 그래프이론
- mrc
- 최단경로
- 기술면접
- 백트랙킹
- ODQA
- 알고리즘스터디
- U_stage
- 글또
- python3
- 이진탐색
- 개인회고
- 다시보기
- Level2
- 알고리즘_스터디
- dfs
- dp
- 주간회고
- 백준
- 파이썬 3
- 프로그래머스
- 이코테
- 부스트캠프_AITech3기
- 부스트캠프_AITech_3기
- 구현
- Level2_PStage
- Today
- Total
국문과 유목민
[일일리포트] Day 35 (Seq2Seq, BEAM) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
Sequence-to-Sequence
단어의 Sequence를 입력으로 받아 다른 Sequence를 출력하는 모델을 Sequence to Sequence (Seq2Seq)모델이라고 한다. Encoder와 decoder구조로 이루어져 있다. <SoS>와 <EoS>라는 토큰을 활용해서 Sequence를 파악한다. Machine Trasnlation에서 사용되는 방법으로, RNN Type 중 many to many에 해당된다.
Sequence-to-Sequence model with Attention
Attentieon은 bottleneck문제에 대한 solution을 제공해준다. 핵심 아이디어는 디코더의 매 time step마다 source sequence의 특정한 part에 집중을 하는 것이다. 해당 모델은 다음과 같은 Process로 동작한다.
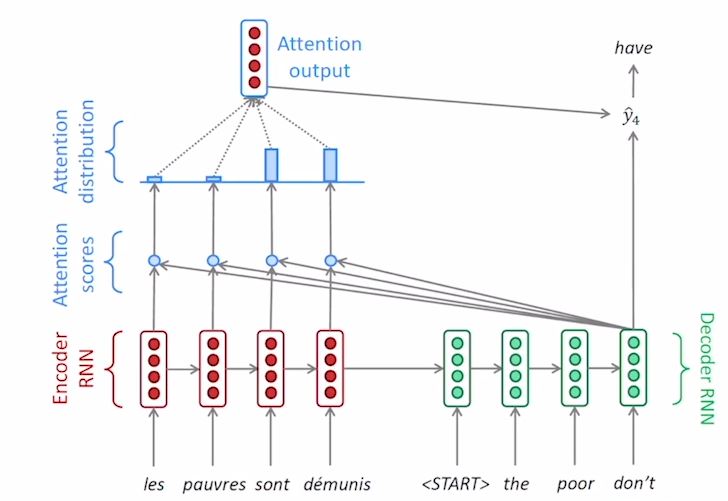
- Encoder RNN에 입력이 들어온다. → Encoder가$h_0$ <START>와 함께 Decoder RNN에 들어간다. 디코더에서는 $h_1^{(d)}$가 나오게 된다.
- $h_1^{(d)}$는 각 인코더 $h_n^{(e)}$와 내적을 수행하게 된다. 이 값들은 디코더의 hidden state vector와 인코더의 hidden state vector간 유사도(Attention scores)가 나온다.
- 위의 값들을 softmax 통과 시키면 logit vector로 나오게 된다. 이 logit vector를 가중치로 사용해 가중 평균으로 Encoder를 계산할 수 있다.
- 가중 평균으로 Encoder를 계산한 값을 통해 output을 만들어 낼 수 있다. 이때, 합이 1이 되는 softmax연산을 수행한 가중평균된 벡터를 Attention Vector라고 한다.
- 위 연산(벡터내적-유사도-softmax-가중평균계산-output연산-예측)을 Decoder의 Hidden state마다 수행해서 값을 예측한다.
Teacher Forcing 매 TimeStep마다 해당 time-step에 해당하는 Ground-Truth만 들어가는 경우를 Teacher Forcing이라고 한다. 그리고 이전 학습 결과의 내용이 반영되면 teacher forcing방법이 아니라고 할 수 있다.
Attention은 Teacher Forcing 방법을 사용하지만, Teacher Forcing을 사용하지 않는 방법이 실제 언어 사용환경과 유사하다. 따라서 모델 학습 시 처음에는 Teacher forcing 방법으로 학습을 진행하다 후반부에는 Teacher Forcing을 사용하지 않는 학습방법을 사용하기도 한다.
Attention의 영향
- NMT의 성능을 올렸다. 디코더가 어느 부분에 집중할 지를 정해줬기에 강하게 됐다.
- Attention은 기존의 Machine Translation이 가지고 있던 bottleneck problem을 해결할 수 있었다.
- 그레디언트 배니싱 문제를 해결할 수 있게 됐다.
- Attention늘 사용함으로 딥러닝 모델의 해석이 가능해졌다. Attention의 분포를 확인함으로써 디코더가 어디에 focusing했는지 확인할 수 있게 됐다. 또한 alignment를 Attention이 스스로 학습하게 됐다.
BeamSearch
Seq2Seq with Attention은 Greedy decoding을 수행하게 된다. 따라서 현재 time step에서 가장 좋아보이는 단어를 선택하기 때문에 결정을 되돌릴 수 있는 방법이 없다. 그렇다고 디코더의 매 타임스텝 t마다 $V^t$를 계산하게 될 경우 많은 계산을 해야하기 때문에 $V$의 사이즈가 커지게 되고, 이에 따라 비용이 증가하게 된다. 따라서 이를 해결하기 위한 방법으로 BEAM이 나오게 됐다.
BeamSearch는 모든 단계를 고려하는 것 방법과 Greedy 방법의 중간지점에 있는 방법이다. 이 방법의 경우 모든 경우를 다 따지는 것보다 효율적이고, 하나만 살펴보는 것보다 신뢰성이 높다. k개(k is the beam size[around 5~10])의 가능한 가짓수를 선정해서 tracking을 진행한다.
Stopping Criterion
- Greedy decoding: <END> token을 만났을때
- beam search: 매 timestep마다 다른 가정에 의해<END> 토큰을 생성할 수 있다. 그리고 <END>토큰이 생성되었을 때, 해당 가정은 임시 메모리에 저장된다. 우리가 별도로 설정한 n개의 가정이 생성되면 beam search가 끝나게 된다.
Finishing Up
완료된 가설들 중 길이가 긴 가설은 Joint probability의 값이 상대적으로 낮고, 짧은 가설일 경우 Joint probability의 값이 상대적으로 높게 나타날 수 있다. 따라서 긴 가설일 수록 점수가 낮아지는 문제를 해결하기 위해, 각 가설을 각 가설들의 단어 개수로 나눠줌으로써 Normalize by length를 수행한다.
$$score(y_1,...,y_t) = \frac{1}{t} \sum_{i=1}^t logP_{LM}(y_i|y_1,...,y_{i-1}, x)$$
BEKU Score
F1Score
BELU Score에 대해 설명하기 전에 F1-Score에 대해 간단하게 설명하겠다. F1-Score는 Precision(정밀도)과 Recall(재현율)을 통해 계산한 Score이다. 다음은 Precision과 Recall을 스타그래프트에 빗대어서 설명해봤다.
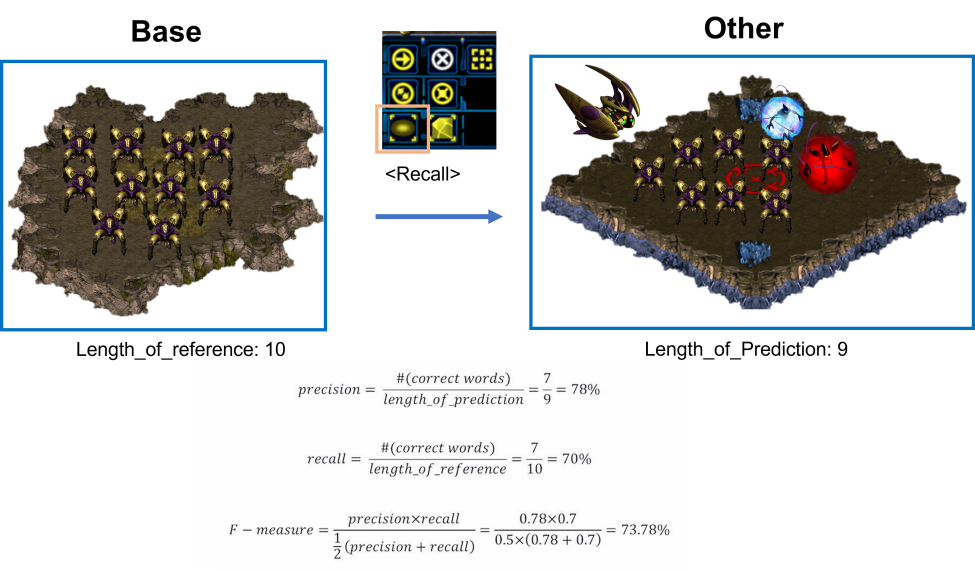
여기서 소환대상은 '드라군'이다.
- Precision: 소환된 것(오른쪽 언덕) 중에 소환대상자가 얼마나 소환됐는가? ($\frac{7}{9}$)
- Recall: 소환대상자(왼쪽 언덕) 중에서 얼마나 소환했는가? ($\frac{7}{10}$)
평균에는 산술 ≥ 기하 ≥ 조화 평균이 다음과 같은 특성을 가지고 있다. 조화 평균은 작은 쪽에 더 가중치를 둬서 평균을 구하는 방식이라고 할 수 있다. 이 얘기를 하는 이유는 F-measure는 precision과 recall 중 작은 값에 가중치를 둬서 조화 평균으로 구한다.
F1-Score로 점수를 계산하면 발생할 수 있는 문제가 있다. 예측값에서 순서가 달라도 해당 Ground-turth의 단어만 다 나오면 f1-measure가 높게 나온다는 문제이다. 위 예시의 경우에는 해당이 되지 않지만, 문장에서는 문장구조가 매우 중요하기 때문에 이러한 문제를 해결하기 위해 BLEU score의 개념이 나오게 됐다.
BiLingual Evaluation Understudy(BLEU)
개별 단어 레벨에서 예측 결과에서 Ground Truth과 얼마나 단어가 겹치는지 뿐만 아니라, N-gram 단위에서 phrase가 얼마나 문법적인지도 고려한다. 따라서 precision만 고려하게 되는데, 실제 ground truth가 얼마나 재현되었나보다 현재 생성된 문장의 의미를 더 중요하게 보려고 하기 때문이다.
BLEU는 기하평균으로 계산을 하게 된다. F1-Score를 계산할 때와 다르게 조화평균을 하지 않는 이유는 작은 값에 더 큰 가중치가 들어가는 것을 막기 위해서이다.
$$BLEU = min(1, \frac{\text{length_of_prediction}}{\text{length_of_reference}})(\prod^4_{i=1}\text{precision}_i)^{\frac{1}{4}}$$
- $min(1, \frac{\text{length_of_prediction}}{\text{length_of_reference}})$: gravity panelty라는게 생성된다. reference(ground truth문장)보다 작은 길이의 문장을 만들었을 경우에는 계산된 precision값을 낮춰주겠다는 의미이다. 여기서 recall을 간단하게 고려하고 있다고 할 수 있다.
BLEU방법은 패턴까지도 고려한 measure이기에, 기계번역에서 평가지표로 자주 사용된다.
▶ Review (생각)
오늘로 이번 주 강의는 모두 정리했고, 기본과제도 다 풀어서 팀원들과 같이 코드리뷰도 진행했다. 오피스아워에서 기본과제 1, 2에 대해서 해설을 진행해주셨는데, 멘토님께서는 내가 3~4시간 동안 풀었던 과제를 한 줄로 간단하게 푸는 코드를 보여주셨다. 그것을 보면서 아직 갈 길이 멀구나...라는 생각이 들었다. 그리고 한편으로는 한번에 코드를 이해하고 구현할 수 있을 정도의 경험을 쌓고 싶다는 생각도 했다.
내일은 기본과제를 해설과 같이 다시 한 번 보고, 내 코드와 비교해서 얻은 인사이트를 정리해볼 계획이다. 또한, 추가적으로 과제를 진행하면서 배웠던 내용들을 다시 한 번 정리해보고자 한다. 그리고 논문 관련해서도 정보를 찾아보고자 한다. 또, '삶의 지도' 작성했던 것도 다시 한 번 보면서 다듬고 해당 내용을 기반으로 '나'에 대해서 정리할 계획이다. 그리고 아마 다음 주 부터는 코딩테스트 공부도 다시 시작할 것 같다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [8주차] 개인 회고 (0) | 2022.03.11 |
|---|---|
| [일일리포트] Day 36 (0) | 2022.03.11 |
| [일일리포트] Day 34 (RNN, LSTM) (0) | 2022.03.08 |
| [일일리포트] Day 33 (NLP Basic) (0) | 2022.03.07 |
| [7주차] 개인 회고 (Level1_프로젝트 정리) (0) | 2022.03.05 |



