
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 단계별문제풀이
- dp
- 이진탐색
- 글또
- Level2
- 정렬
- 그리디
- 파이썬 3
- mrc
- 백준
- Level2_PStage
- 그래프이론
- 프로그래머스
- 백트랙킹
- U_stage
- 부스트캠프_AITech_3기
- 구현
- 이코테
- Level1
- 알고리즘_스터디
- 다시보기
- dfs
- 알고리즘스터디
- 주간회고
- 기술면접
- 개인회고
- 최단경로
- 부스트캠프_AITech3기
- python3
- ODQA
- Today
- Total
국문과 유목민
[일일리포트] Day 59 (Relation Extraction Data) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
관계 추출 데이터 이해
데이터를 만들기 전에 과제 이해가 선행되어야 한다. 그리고 과제를 이해한다는 것은 관련 레페런스를 찾아본다는 의미도 내포되어 있다. 관계 추출 Task를 이해하기 위해서는 개체명 인식 Task를 이해해야 한다.
아래의 Task들은 개체를 보는 관점, 대상 개체의 분류 레이블 차이, 관계에 대한 주석 여부와 어떻게 주석하는지, 참조 자원에서 차이점이 존재한다.
개체명 인식 (NER, Named Entity Recognition)
개체명이란 인명, 지명, 기관명 등 고유명사나 명사구를 의미한다. 개체명 인식 Task는 문장을 분석 대상으로 삼아서 문장에 출현한 개체명의 경계를 인식하고, 각 개체명에 해당하는 태그를 주석하는 작업이다.
NER Task에서 유명했던 Challenge로 MUC-7과 CoNLL 2003가 있다. 한국의 경우 TTA 표준이라고 해서 개체명이 매우 세분화되어 있다. 그 이유는 초기 프로젝트의 방향이 지식을 체계화하는 방향이었기 때문에 개체명이 세분화되었고 한다.
데이터 구축시 문제점으로는 2개 이상의 태그로 주석될 수 있는 개체명이 있다. 이 경우 맥락에 기반한 주석을 한다.(작업자에 따라 통일성 저해 가능) 또한, 주석 대상의 범주를 설정하기 어렵다는 문제가 있는데 이는 구체적 범주 및 기준을 명시하는 것으로 해결을 할 수 있다.
관계 추출 (RE, Relation Extract)
관계 추출은 문장에서 나타난 개체명(Entity) 쌍의 관계를 판별하는 task이기 때문에 앞서서 개체명 인식이 선행되어야 한다. . 개체명 쌍은 관계의 주체(Subject와 대상(Object)으로 구성된다.
데이터 구축시 문제점으로 한국어 데이터 현실에 맞지 않는 주석이 생기는 경우가 있는데, 이럴 경우 tag 통폐합 및 추가를 진행해 문제를 해결한다. 그리고 특정한 주제가 있을 때, 특별한 태그를 추가해서 데이터를 잘 표상할 수 있게 체계를 갖춰야 한다.
개체명 연결(EL, Entity Linking)
개체명을 인식하고 모호성을 해소하는 과제를 결합한 것이다. 텍스트에서 추출된 개체명을 지식 베이스와 연결해 모호성을 해소한다.
EL 구축시 문제점으로는 적합한 KB(Knowledge base) 선정의 문제가 있다. KB를 구축하는 것 자체가 많은 비용과 자원이 드는 일이므로 이에 대한 대비가 필요하다.
그렇다면 이러한 데이터를 만드는 이유에 대해서 얘기해보겠다. NER, RE, EL은 기본적으로 비구조화된 텍스트에서 정보를 추출해 구조화하려는 것이 목적이다. 따라서 이 과정에서 KB가 활용되기도 하고, 이 결과물이 KB가 되기도 한다. 정보처리의 관점에서 구조화된 정보의 활용도가 높기 때문에 이러한 시도는 앞으로도 계속 될 것이라고 한다. 이렇게 만들어진 데이터들은 검색 시스템이나 HR 챗봇, 구글 핀포인트(Document Understanding) 등애서 활용된다.
관계 추출 관련 논문 읽기
데이터 제작 전 선행 연구에서 어떤 식으로 데이터를 제작했는지 확인할 수 있다. 관계 추출 관련 논문으로는 TACRED데이터를 다루고 있는 해외 논문 하나와 KLUE데이터를 다루고 있는 국내 논문에 대해서 간단하게 다뤄보고자 한다.
1. Position-aware Attention and Supervised Data Improve Slot Filling
2. KLUE: Korean Language Understanding Evaluation
Position-aware Attention and Supervised Data Improve Slot Filling
모델과 함께 TAC Relation Extraction Dataset(TACRED)을 제시하고 있다. Slot Filling과제는 Sub, Obj에 해당하는 개체가 주어지고 그것에 대해 Relation 태그를 채우는 것이다. 실제 논문에서 데이터셋 부분의 분량은 많지 않은데, 추가적으로 Appendix에서 데이터 구축 과정에 대해 좀 더 설명이 되어있다. 기존 데이터셋에 비해 Relation이 좀 더 세분화되어있고, 문장이 좀 더 복합해졌다고 얘기한다.
KLUE: Korean Language Understanding Evaluation
Overview에서 Task에 대한 설명을 하고 있다. Data Construction에서는 어떤 데이터를 가져왔는지에 대해서 설명한다. 또한 도매인이 달라짐에 따라서 추가된 새로운 관계에 대해서 추가적으로 설명하고 있다.
KLUE데이터 구축 과정을 보면 우선, 엔티티를 주석하는 과정과 엔티티 쌍을 선택하는 과정을 거친다. 엔티티 주석 단계에서는 한국어 ELECTRA를 활용해 NER Task를 수행한 이후 Entity의 쌍을 선택했다고 한다.
Annotate Relations에서는 어떤 도구를 사용해서 주석 작업을 실시했고, 몇 명의 작업자들을 어떻게 선정했는지에 대해서도 얘기를 한다. 마지막으로 Evaluation에 F1 score를 사용했다고 설명한다.
관계 추출 데이터 구축
과제 정의
과제 정의 시 필수적으로 고려할 요소는 다음과 같다. 과제의 목적, 데이터 구축 규모, 원시 데이터, 데이터의 주석 체계, 데이터 주석 도구, 데이터의 형식, 데이터 검수, 데이터 평가지표
- 데이터 구축 규모: 기간 내 수집 가능한 데이터를 현실적으로 선정해야 하고, 원시 데이터의 출처를 생각해야 한다. RE Task에 해당하는 문장을 구하기 위해서는, 둘 이상의 개체와 개체 간의 관계를 추출할 만한 문장이 포함된 텍스트를 선정해야 한다. 구어의 경우 sub나 obj가 누락된 형태가 많아 문어 데이터를 주로 활용한다.
- 데이터의 주석 체계: Relation Class와 Description 추가적으로 예제를 넣어주면 좋다. 그리고 주석작업을 실제로 100개 정도 해봤을 때 주석 체계가 잘 맞는지, 맞지 않는지 확인할 수 있다.
- 데이터 검수: 데이터 형식의 정확도, 관계 레이블의 정확도, 관계 추출 정확도를 확인해야 한다. 또한, 검수 규모도 전수조사를 진행할 지 특정 비율만 조사를 진행할 지에 대해서 생각해야 한다.
- 데이터 평가: 작업자 간 일치도나 모델 성능 평가가 있다.
- 작업자 간 일치도 (IAA, Inter-Annotator Agreement): Fleiss kappa(TACRED), Krippendorff's a(KLUE) [결측치가 있어도 고정해서 사용할 수 있다.]
- 모델 성능 평가: 정밀도, 재현율, F1, Micro F1(불균형한 데이터에 대한 지표), AUPRC 사용
구축 프로세스 설계
데이터 구축 프로세스는 그래프나 표로 나타낼 수 있다. 하단 데이터 구축 프로세스는 관계추출 데이터 뿐만 아니라 다른 데이터를 구축하는데도 적용될 수 있다.
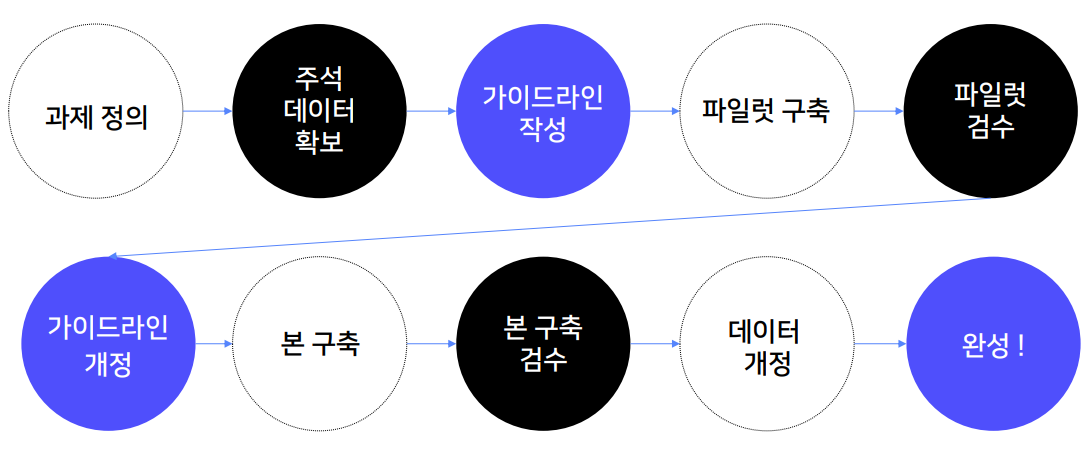

가이드라인 작성
주석 작업을 위해서는 가이드라인이 필요하다. 가이드라인은 최대한 꼼꼼하게 작성해야 더 좋은 데이터를 얻을 수 있다. 작업 목적과 작업 도구 사용법에 대해 가이드라인을 작성해야 한다. 작업 대상 문장과 아닌 문장 구분 기준을 설정해야 한다. 그리고 마지막으로 레이블별 주석 기준을 꼼꼼하게 선정해야 한다.
(예시: 주체와 객체 확인. 주체와 객체의 개체명을 확인하고, 개체명의 관계를 주어진 목록에서 선택한다. 작업 대상 문장이 아닌 경우 reporting을 한다.)
마지막으로 유의해야할 점으로 가이드라인은 꼼꼼하게 정의하는 것도 중요하지만, 너무 길어지면 작업자들이 잘 안 볼 수도 있기 때문에 가독성적인 측면도 고려해서 작성해야 한다.
▶ Review (생각)
오늘 강의는 앞서 배운 데이터 제작 강의를 '관계 추출 데이터 구축'이라는 조금 더 구체적인 주제를 다뤘다. 앞서 배웠던 내용들이랑 겹치는 부분들이 좀 있었던 것 같긴 하지만, 앞서 배웠던 내용들을 개괄적으로 볼 수 있어서 좋았다.
데이터 제작 수업을 들으면서 예전에 데이터 라벨링 작업을 했던 기억이 생각났다. 그때 매번 지침이 달라져서 데이터 라벨링을 진행하는데 꽤 힘들었었다. 지금 생각해보니 데이터 구축 프로세스나 가이드라인이 잘 잡혀있지 않았기 때문이었다. 그래서 그런지 마스터님께서 말씀해주셨던 과제 정의나 구축 프로세스 설계, 가이드라인 작성이 왜 중요한지에 대해서 좀 더 직접적으로 다가왔던 것 같다. 만약, 현업에서 데이터 구축을 하게 될 경우가 생긴다면 오늘 배운 내용들을 기준으로 잡을 수 있을 것 같다.
추가적으로 오늘 새로운 멘토님과 멘토링을하고, 변성윤 마스터님의 두런두런 시간을 가졌다. 부스트캠프에서 좋은 교육을 받는 것도 좋지만, 이렇게 현업자분들과 얘기할 수 있고 질문할 수 있는 기회가 주어진다는 것도 너무 좋은 것 같다. 오늘 나눴던 말씀이나, 말씀해주셨던 말씀들을 잘 기억해서 미리미리 이력서도 준비하고 관심있는 회사들에 대해서도 생각해봐여겠다. 이전 멘토님께 받은 이력서 피드백부터 빨리 수정해서 슬랙에 올려야겠다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 61 (가이드라인 작성) (0) | 2022.04.15 |
|---|---|
| [일일리포트] Day 60 (Relation-Map) (0) | 2022.04.14 |
| [일일리포트] Day 58 (데이터 제작2) (0) | 2022.04.12 |
| [일일리포트] Day 57 (데이터 제작1) (0) | 2022.04.11 |
| [12주차] 개인 회고 (Level2_KLUE_프로젝트 정리) (1) | 2022.04.08 |



