
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 기술면접
- dfs
- 최단경로
- python3
- 이코테
- 백준
- 프로그래머스
- 부스트캠프_AITech_3기
- 부스트캠프_AITech3기
- 정렬
- ODQA
- 주간회고
- 파이썬 3
- dp
- 그래프이론
- 그리디
- 백트랙킹
- 단계별문제풀이
- Level1
- U_stage
- 구현
- 다시보기
- 알고리즘스터디
- Level2_PStage
- mrc
- 개인회고
- 알고리즘_스터디
- 글또
- Level2
- 이진탐색
- Today
- Total
국문과 유목민
[일일리포트] Day 37 (Transformer1) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
Transformer
Transformer는 'Attention is all you need'라는 모델에서 나온 개념으로 RNN모듈에서 벗어난 새로운 방법이다. RNN은 입력으로 들어오는 데이터가 많아질수록 어쩔 수 없이 gradient vanishing문제가 발생하게 된다. 따라서 이러한 문제를 해결하고자 나온 것이 바로 Transformer이다. Transformer는 아래 그림처럼 Attetntion만으로 seq 데이터를 입력으로 받아 다른 seq데이터를 출력하는 모델이라고 할 수 있다. Transformer에 관한 이번 강의에서는 Bottom-up방식으로 설명을 하셔서 정리가 쉽지 않아, 설명은 해당 사이트의 자료를 활용해 Top-down방식으로 정리하도록 하겠다.

지금까지 Transformer가 어떻게 생겼는지 먼저 살펴봤다 (SelfAttention을 파다보면, Transformer가 어떤식으로 생겼는지 까먹을 수 있다). 이제 Self Attention에 대해 살펴보고자 한다. Self Attention Layer에서는 model이 한 입력 seq 내에서 각 워드를 처리할 때, 해당 워드를 제외한 다른 단어들의 위치를 살펴 해당 워드의 Encoding을 개선할 수 있는 단서를 찾는 일을 수행한다.

간단하게 각 벡터들을 설명해보자면 Query벡터는 주어진 벡터 중에서 어느 벡터를 가져올 지에 대한 기준이 되는 벡터이다. Key벡터는 Query벡터의 재료 벡터라고도 불리는데, Query벡터에서 여러 개의 Key벡터 중 어느 벡터가 높은 유사도를 가지고 있는지 확인해서 가져오는 데 사용된다. Value벡터는 앞서 계산한 유사도(가중치)를 Softmax한 값과 연산을 해 가중평균을 구해서 Output을 내는 데 사용된다. Key와 Value벡터는 Input으로부터 만들어진다.

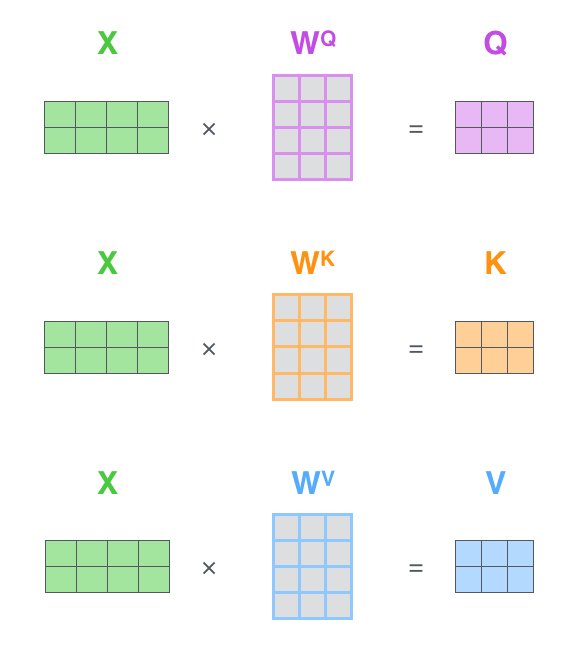

앞서 전체적인 흐름을 간단하게 봤고, 조금 더 설명을 붙여보고자 한다. 앞서 나온 입력벧터는 모두 Encoding Vector를 계산하는 과정에 들어가게 된다. Seq가 길다고 하더라도 이들은 동일한 Key와 Value벡터로 변환이 된다. 그리고 Query벡터와 Key벡터의 내적으로 나온 유사도만 높다면, 멀리 있던 단어의 정보를 손쉽게 가져올 수 있다. 그래서 RNN이 가지고 있는 long Term Dependency문제를 근본적으로 해결한 Sequence 인코딩 방법이라고 한다.
그리고 위의 식을 수학적인 연산으로 바꿔보자면 다음과 같은 식이 나오게 되는데
$$A(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$$
$\sqrt{d_k}$ 연산을 하는 이유에 대한 설명이 없어 간단하게 해보겠다. $QK^T$연산으로 인해서 차원이 올라가게 되면,표준편차가 달라져서, softmax out의 확률분포가 의도치 않게 한 곳에 몰릴 수가 있다. 모듈의 내적 기반 유사도를 구할 때 scaling을 추가해주는 것이다. 실제로 학습에서 softmax output을 적절한 정도로 범위조절하는 것이 중요하다고 한다.
추가적으로 해당 식에서 연산 시 고려해야 하는 특징들이 있기는 하다. 각 행렬에 대한 차원을 맞춰줘야 한다고는 하는데 실제 Transformer 구현 상으론 동일한 shape로 mapping된 Q, K, V가 사용되어 각 matrix의 shape는 모두 동일하다고 하니 간단하게만 정리하겠다.
$$(|Q| \times d_k) \times (d_k \times |K|) \times (|V| \times d_v) = (|Q|\times d_v)$$
후에 Transformer 정리2 에서 이어집니다.
Transformer에 관한 더 자세한 설명은 아래의 링크를 확인해보면 더 좋다.
참고링크: http://jalammar.github.io/illustrated-transformer/
▶ Review (생각)
오늘은 너무 아파서 1강만 정리를 하고 넘어갔다. 저녁에 자가검진을 했는데 코로나가 걸렸다는 것을 이제서야 알아버렸다. 내일은 특강이 있는데 강의를 잘 들을 수 있을지 걱정이다. 일단 간단하게 정리를 끝내고 보강을 하는 것으로 해야겠다. (보강 完)
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 39 (Transformer2) (0) | 2022.03.16 |
|---|---|
| [일일리포트] Day 38 (0) | 2022.03.15 |
| [8주차] 개인 회고 (0) | 2022.03.11 |
| [일일리포트] Day 36 (0) | 2022.03.11 |
| [일일리포트] Day 35 (Seq2Seq, BEAM) (0) | 2022.03.10 |



