
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 부스트캠프_AITech_3기
- 백준
- 알고리즘_스터디
- Level2
- 주간회고
- 프로그래머스
- dfs
- python3
- dp
- 글또
- 그리디
- 다시보기
- 파이썬 3
- mrc
- Level1
- ODQA
- 부스트캠프_AITech3기
- 백트랙킹
- 구현
- 최단경로
- 단계별문제풀이
- 기술면접
- Level2_PStage
- 개인회고
- 정렬
- 그래프이론
- 이코테
- U_stage
- 이진탐색
- 알고리즘스터디
- Today
- Total
국문과 유목민
[일일리포트] Day 39 (Transformer2) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
앞선 Transformer 정리에서 이어집니다. 그리고 해당 사이트(http://jalammar.github.io/illustrated-transformer/)의 자료로 정리를 하며 중간중간 강의에서 배운 내용이 들어갑니다.
Transformer: Multi-Head Attention
Transformer의 성능을 더 발전시키기 위해서 'Multi-Head Attention'이라는 방법을 사용합니다. 말 그대로 Attention을 여러 번 한다고 생각하면 됩니다. 'Multi-Head Attention'은 2가지 방법으로 성능을 올리고자 합니다. 첫 번째로는 Attention block을 여러 개 만듦으로써 Self Attention이 다양한 위치에 집중할 수 있게 하는 것입니다. 그리고 두 번째로는 Self Attention Layer에 Representation Subspaces을 주는 것입니다. 각 Attention Head에 대해 다음과 같은 Set이 여러개 생기는 것입니다.
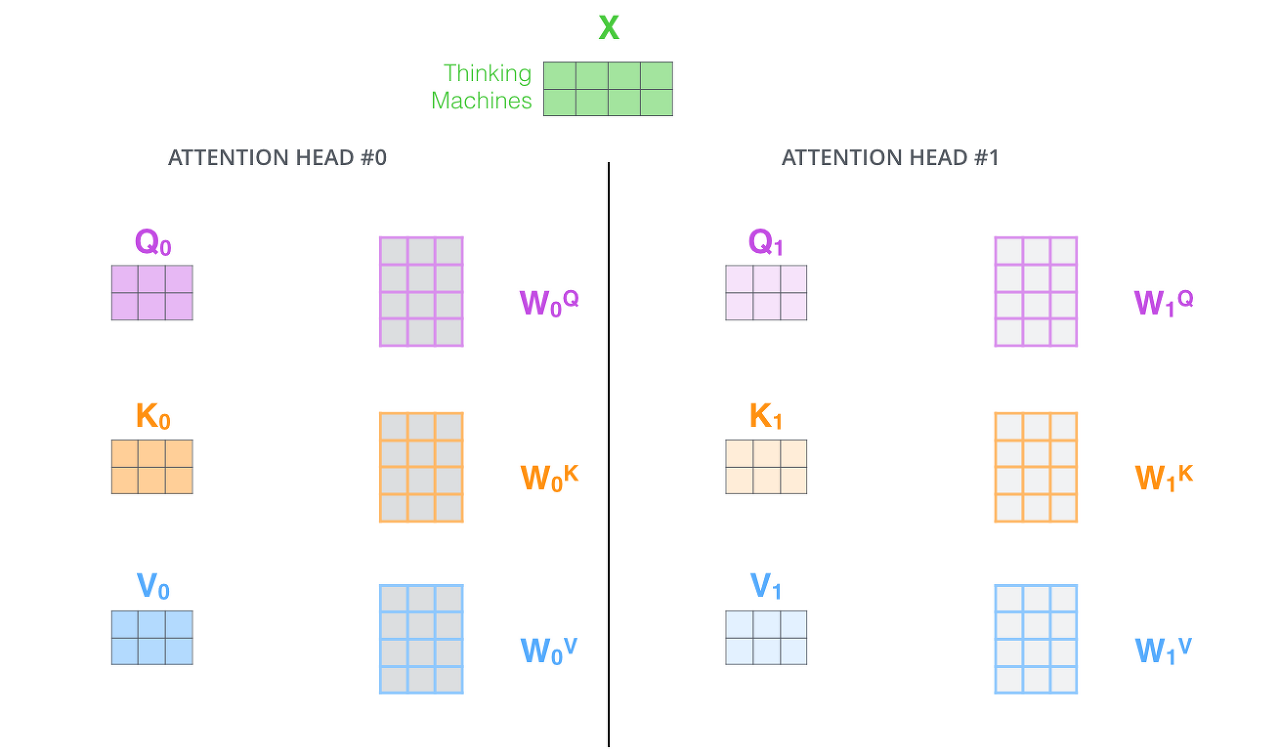
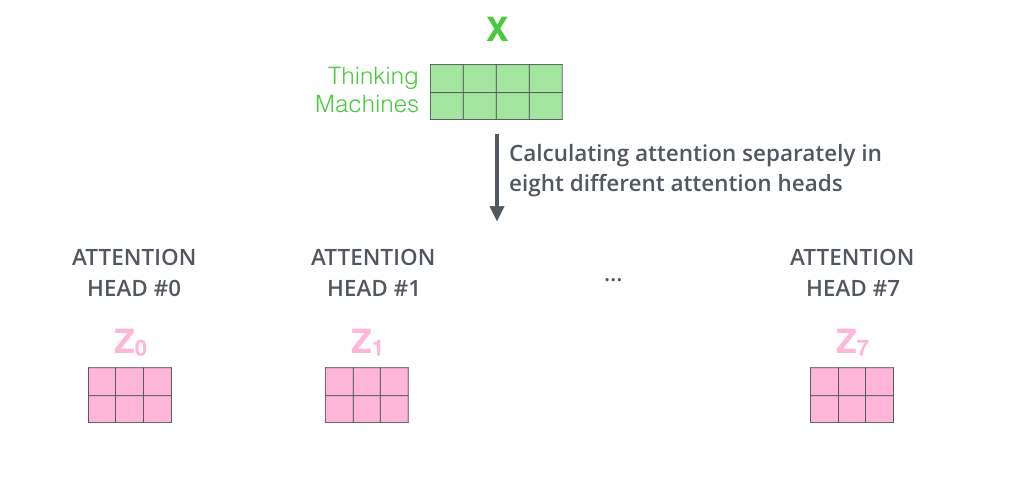

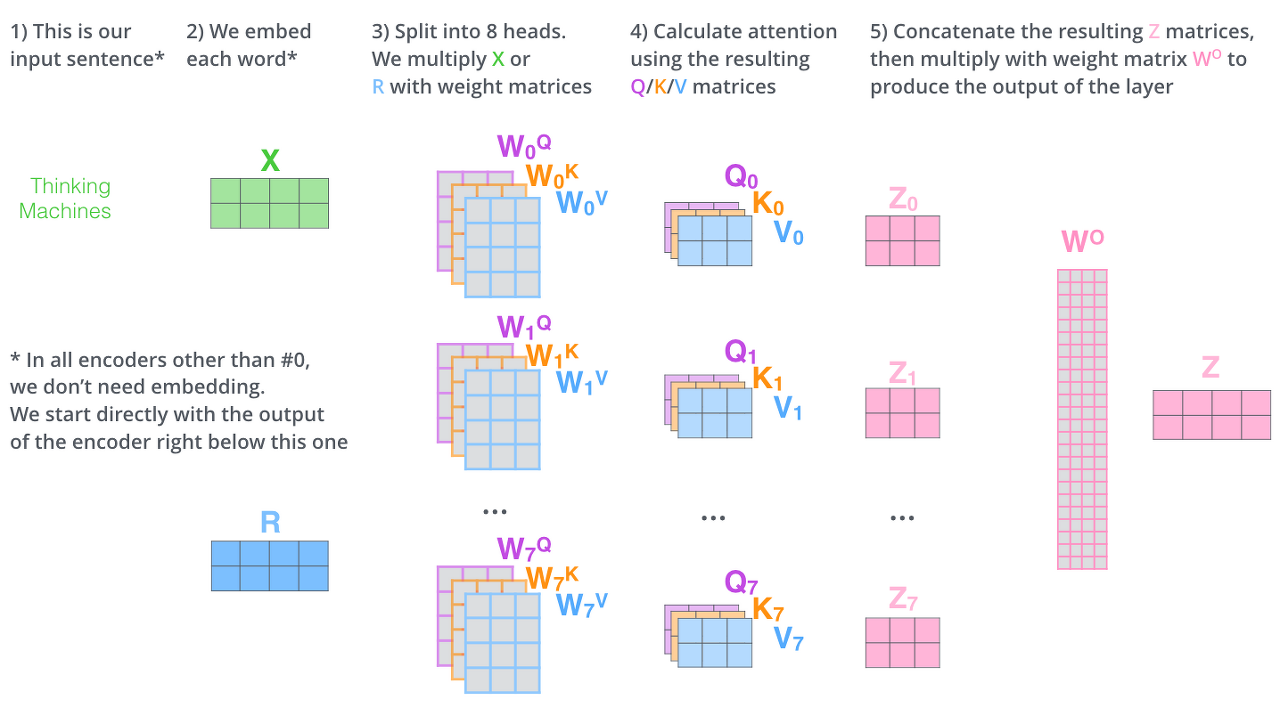
여기서 끝이 아니다. Transformer연산을 하게 되면 softmax연산 과정에서 가중평균을 낼 떄, 최종 output벡터는 순서를 무시한다. 따라서 순서 정보를 얻어내기 위해서 Positional Encoding을 사용해야 한다. 이름만 듣고 어렵다고 생각할 수 있지만, 실체를 보면 더 어렵다.
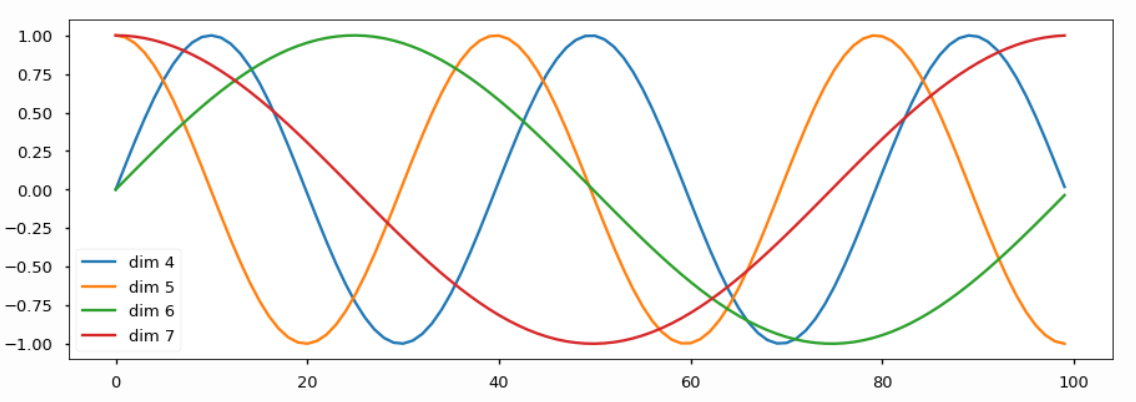
각 순서를 특정지을 수 있는 유니크한 상수 벡터를 각 순서에 등장하는 워드 입력벡터에 더해주는 것을 Positining Encoding이라고 한다. 위치를 나타내는 finger print벡터를 sin혹은 cos 그래프에서 얻어낼 수 있다. 이 방법을 활용하게 되면 위치별로 서로 다른 벡터가 더해지게 하는 방법으로 위치가 달라지면 출력 인코딩 벡터도 달라지는 방법으로 순서라는 정보를 Transformer모델이 다룰 수 있도록 했다.
Transformer는 Block-Based Model로, 이전에 Transformer는 여러 개의 인코더 블록이 존재한다고 했다. 그리고 각 블록은 Multi-head Attention과 Two-layer-feed-forward NN (with ReLU)로 이루어져 있다고 알고있다. 그런데 사실 각 Layer의 연산(SelfAttention, FeedForward)을 진행한 후 Residual Connection과 LayerNormalziation step이 진행된다.

Layer Normalization은 주어진 값들의 평균을 0 분산을 1로 만들어준 후, 학습 가능한 매개 변수를 사용하여 각 시퀀스 벡터의 Affine(선형) 변환한다. (Affine Transformation: $y = ax + b$)
결국 다음과 같은 프로세스로 진행된다고 한다. Residual Connection을 진행해 변환을 완료한 이후, Word별로 가지고 있는 인코딩 벡터를 추가적인 FullyConnectedLayer에 추가를 시킨다. 각 인코딩 벡터를 변환하고 동일하게 Residual Connection을 하고 다시 Layer Norm alization을 진행한다.

마지막으로 Decoder연산이 남았다. Decoder연산에 대한 설명이 남았다. Encoder는 입력 Sequence를 처리해 출력에서 Attention Vector K와 V의 Set으로 변환된다. 해당 Vector들은 각 decoder의 'encoder-decoder attention'에서 입력 Sequence가 알맞은 place를 찾는데 도움을 줍니다. 다음과 같은 Process를 통해서 Decoder가 동작합니다.
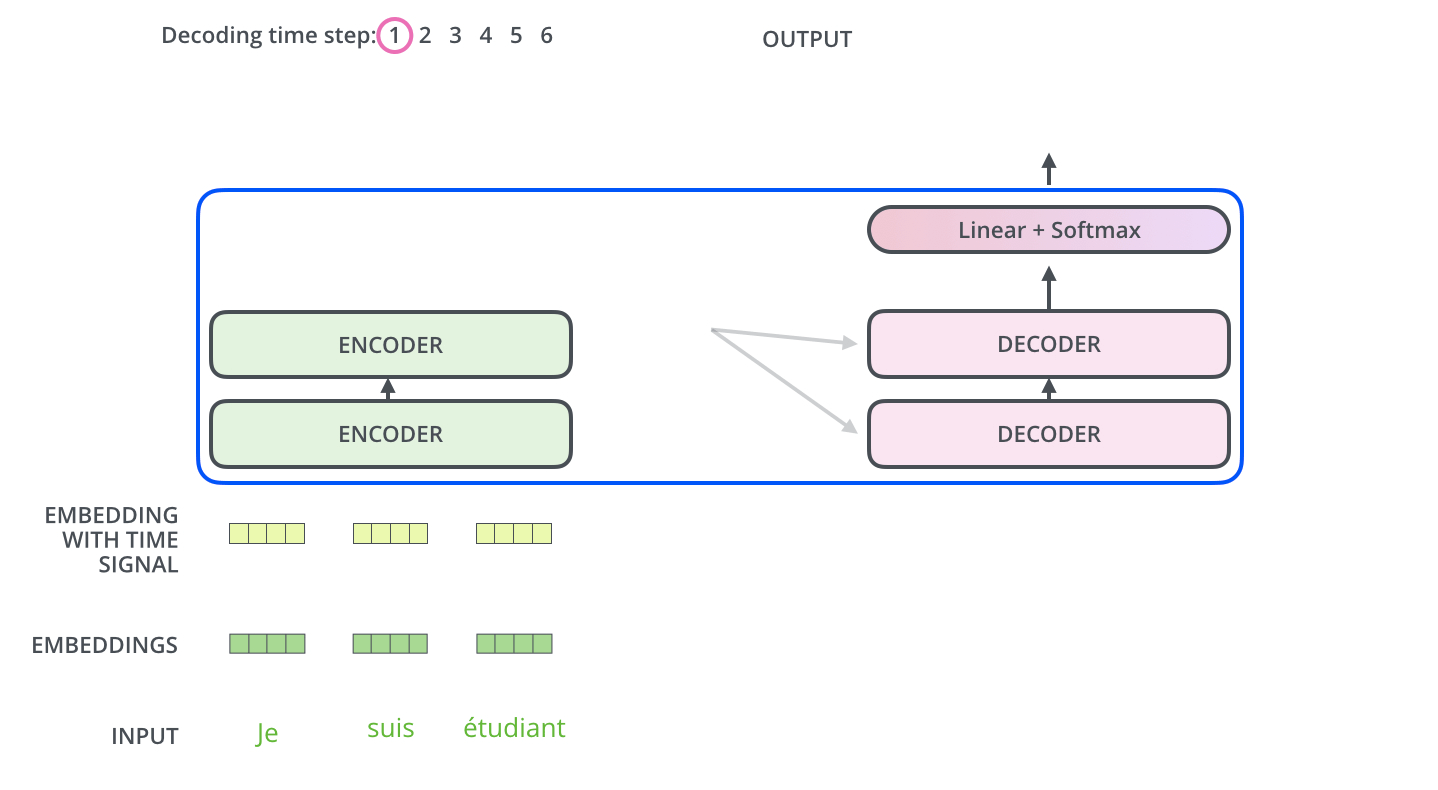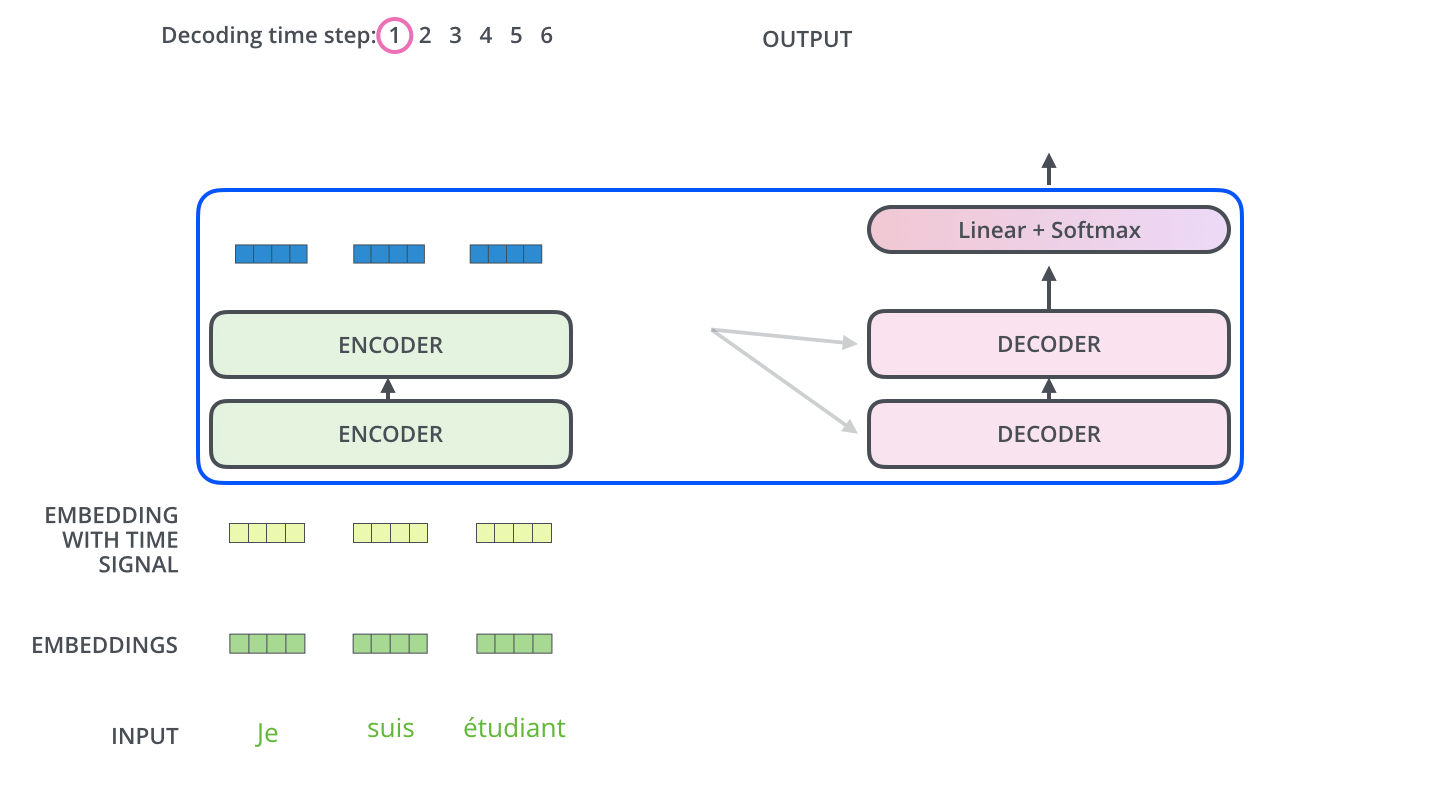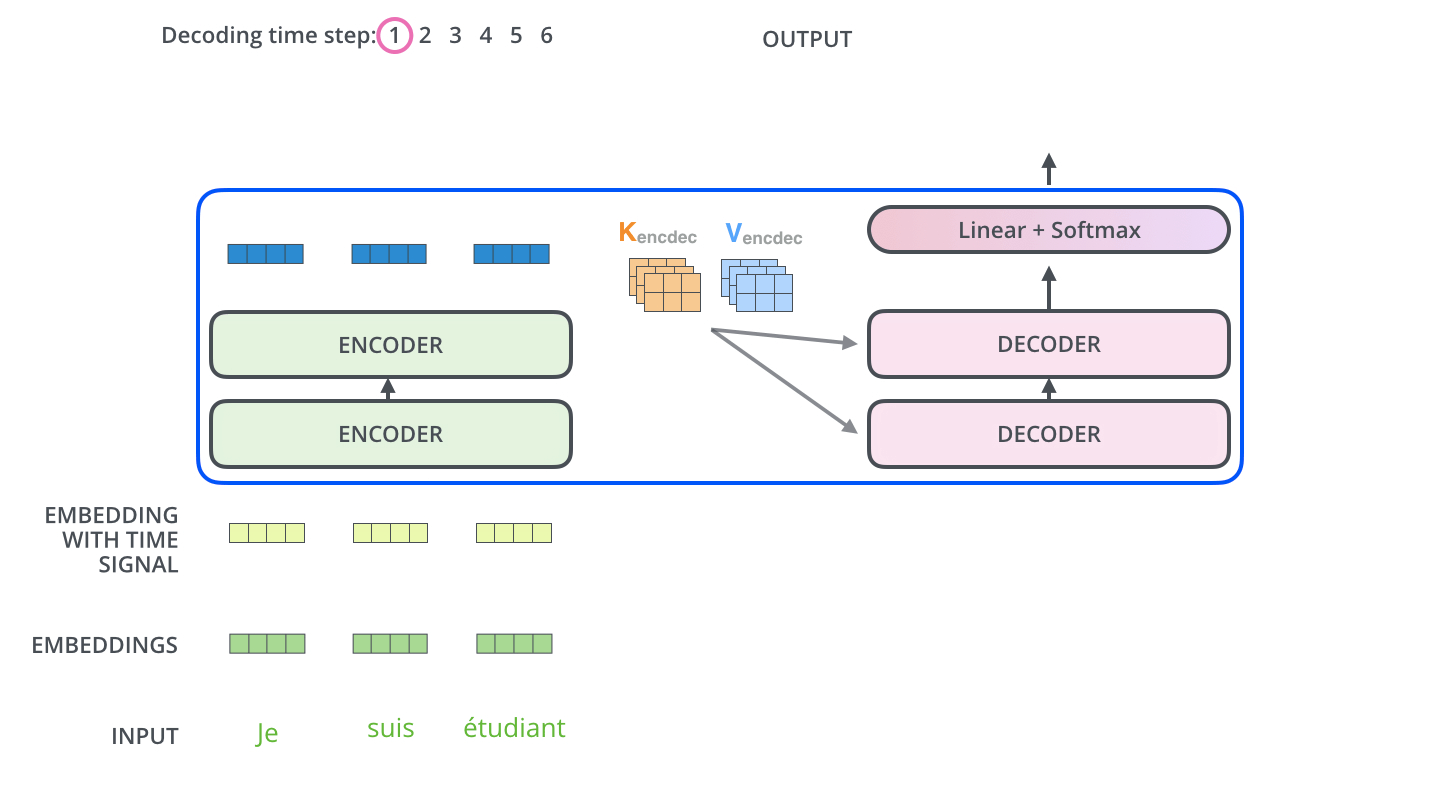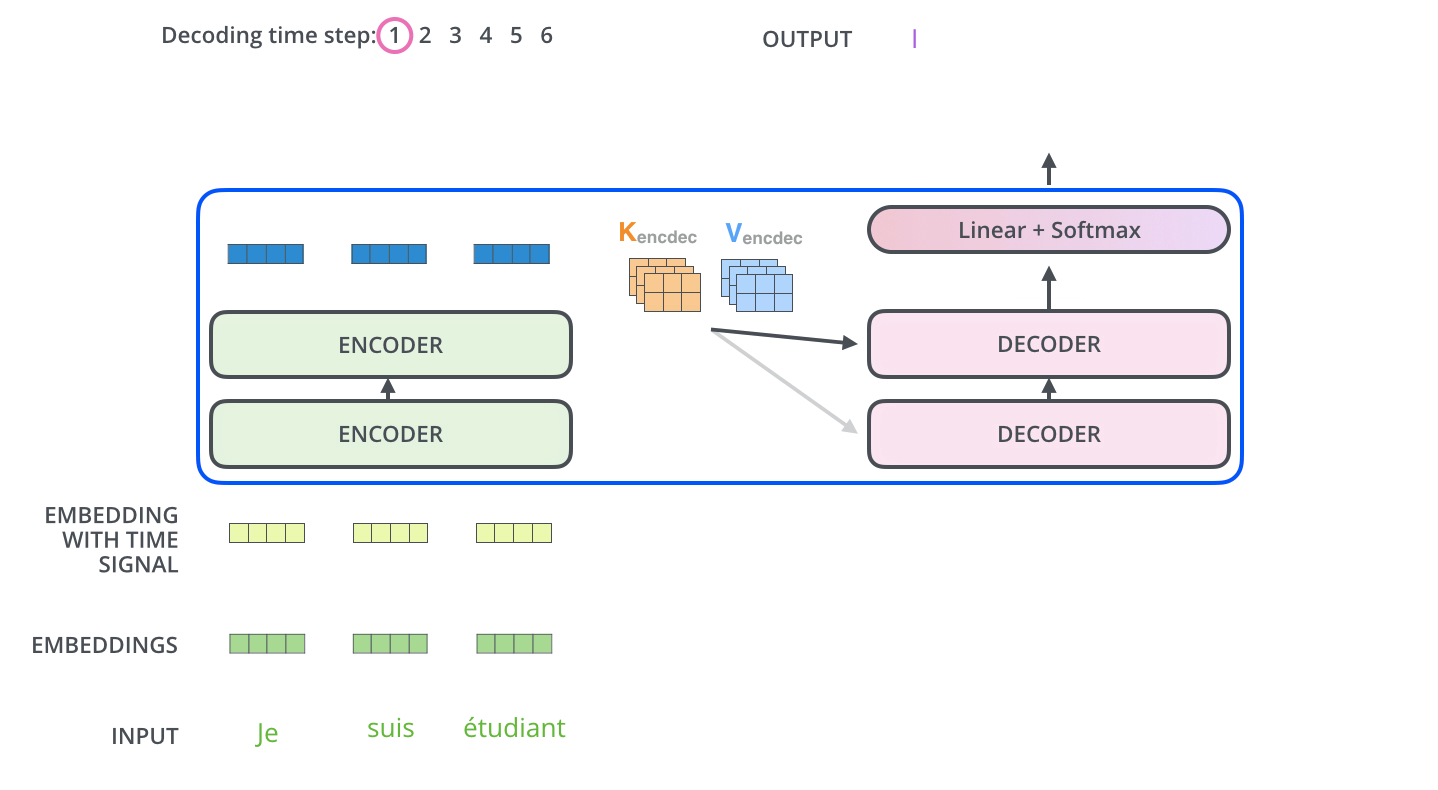
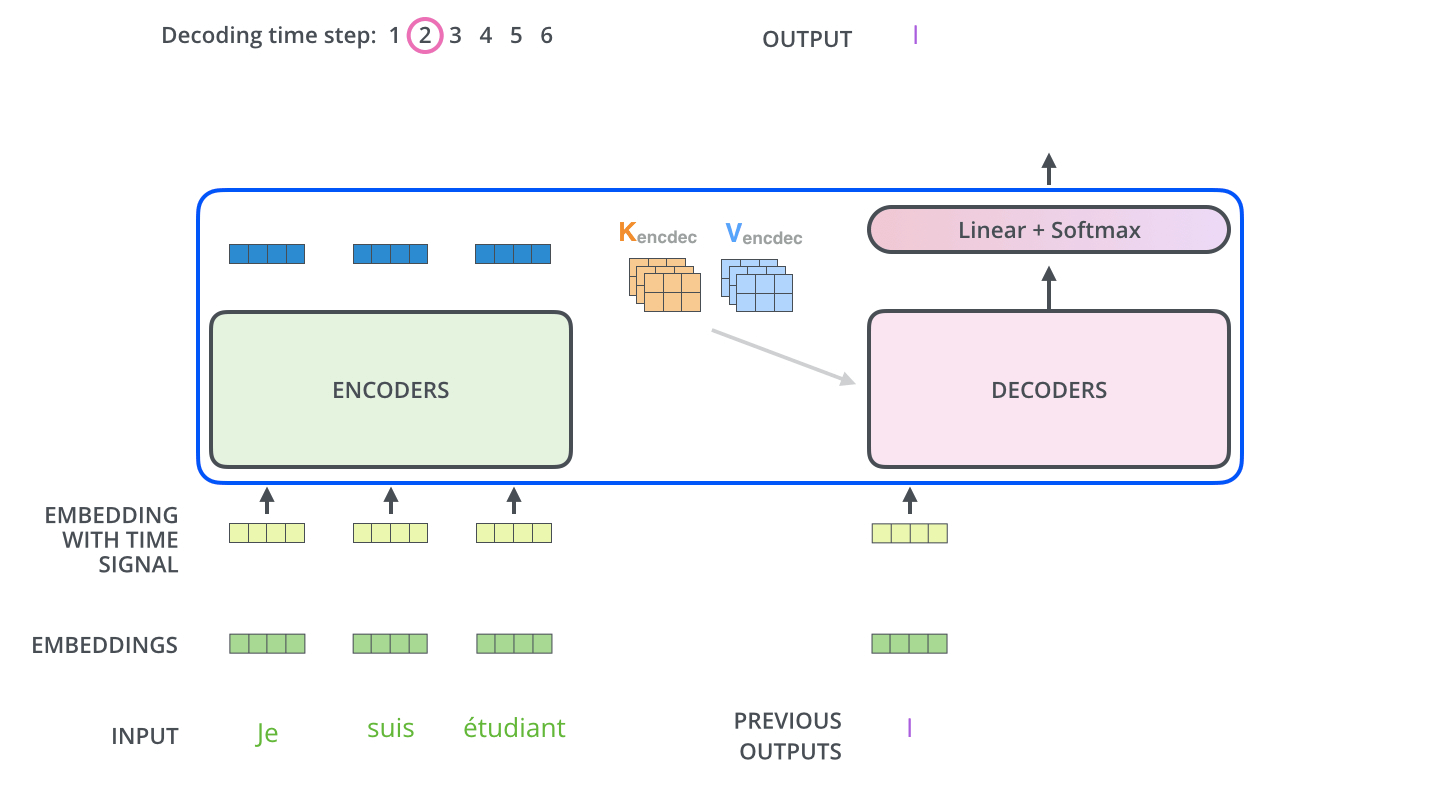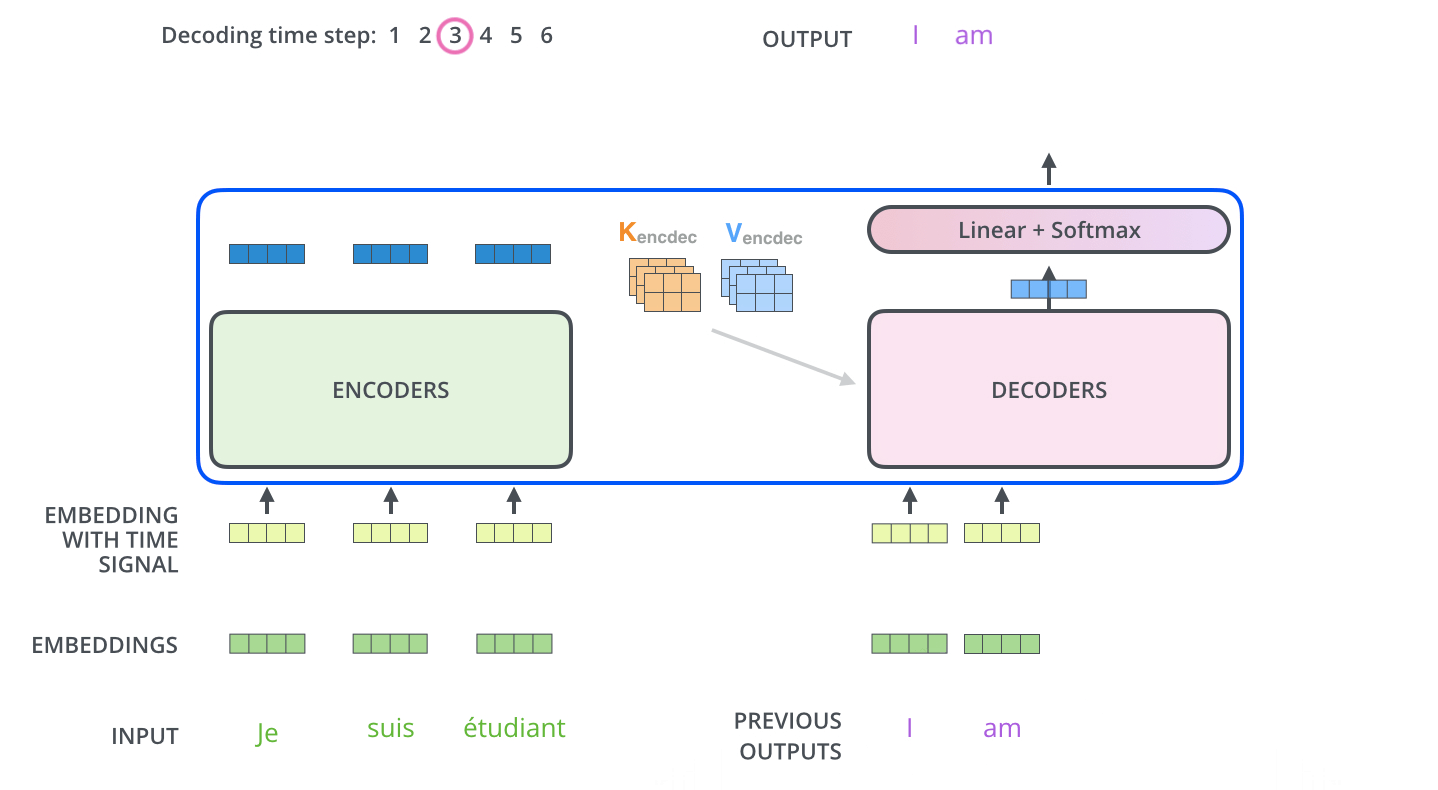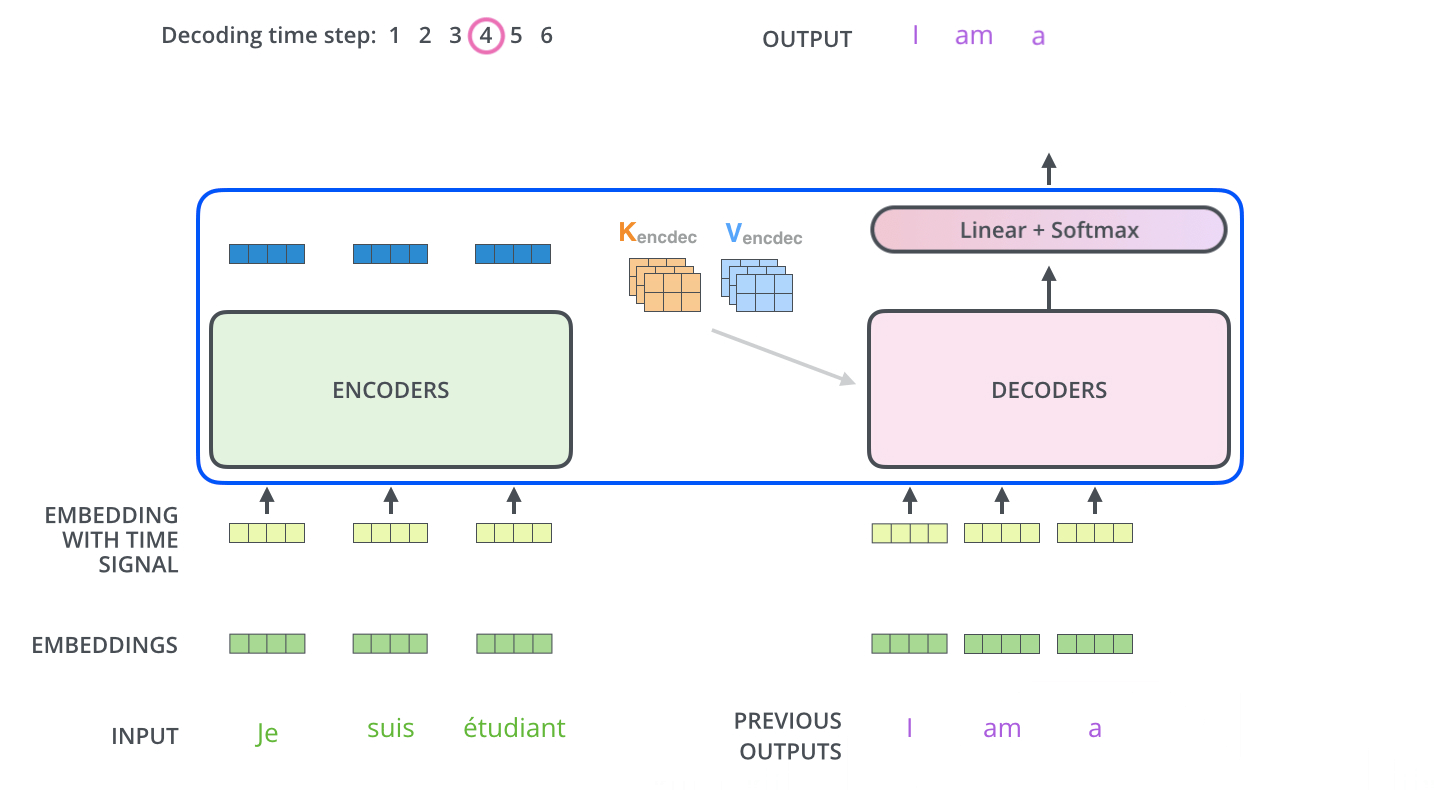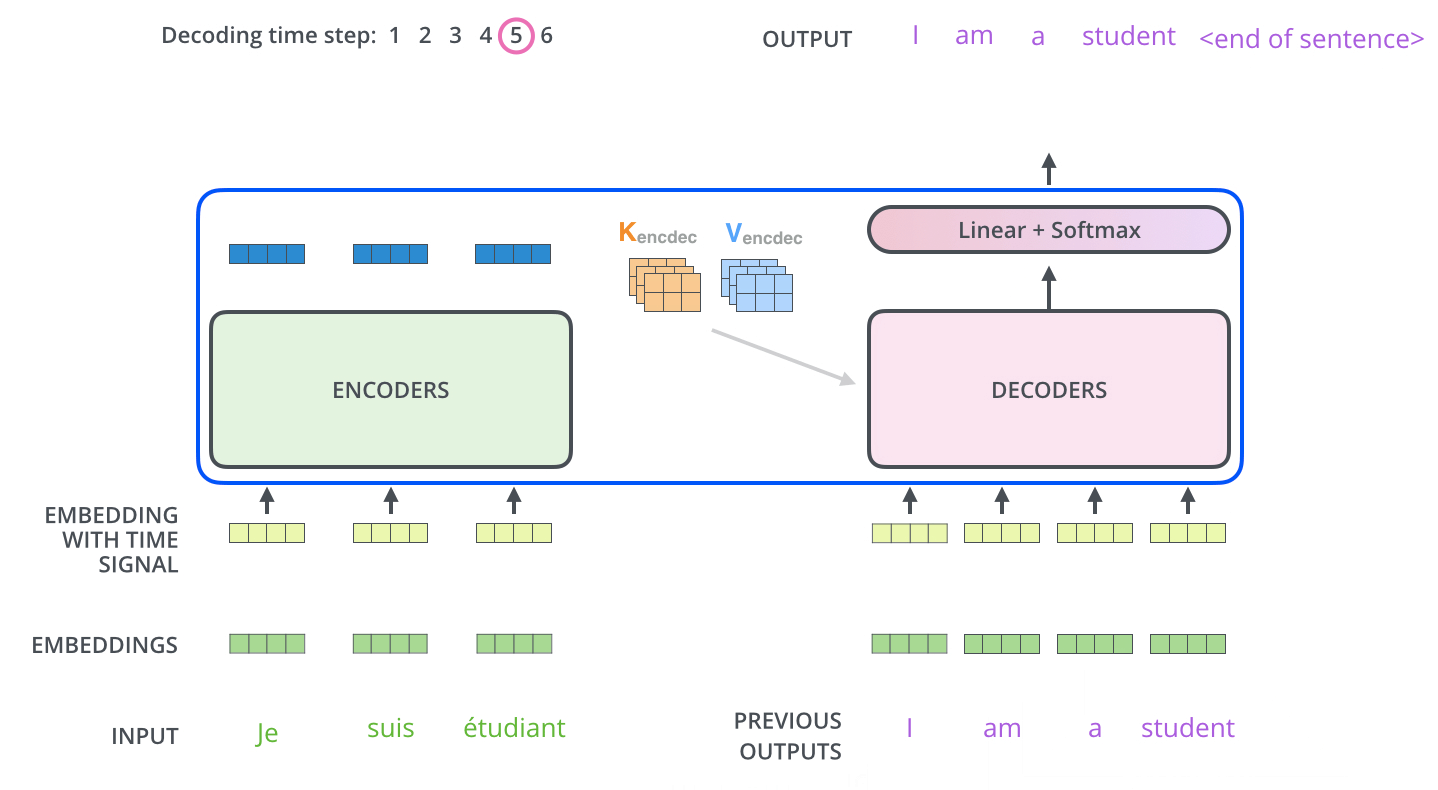
Decoder의 과정은 앞서 설명한 Encoder의 과정과 유사합니다. Positional Encoding(Embedding With Time Signal)도 하고, 내부적으로 Add+Normalization연산을 수행합니다. 하지만 Attention Layer는 인코더와 약간 다른 방법으로 동작합니다. Decoder에는 Self Attention Layer와 Encoder-Decoder Attention 2개의 Attention Layer가 존재합니다.
Self Attention Layer: Decoder에서는 출력 시퀀스 내 이전 위치에만 대응할 수 있어야 합니다. 따라서 Self-attention 계산에서 softmax step 전에 미래 위치를 마스킹(-inf로 설정 혹은 0으로 설정)함으로써 미래를 보지 못하게 하고 계산을 합니다.
Encoder-Decoder Attention: 인코더의 Multi-Head Self Attention과 동일하게 동작합니다. 하지만 그 아래의 레이어에서 Query 매트릭스를 작성하고, Encoder의 출력으로부터 키와 값 매트릭스를 가져와 계산을 합니다.
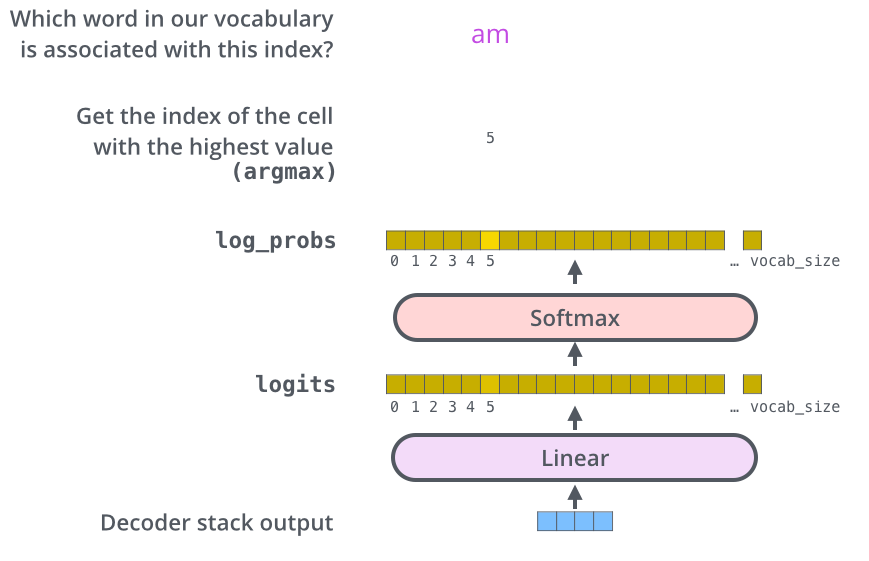
이제야 끝이 보인다. 마지막으로 Decoder Stack에서 나온 벡터(float)를 단어(String)로 바꾸기 위해서 최종 Linear Layer작업과 Softmax Layer 작업을 진행하면 된다.
Linear Layer(선형 레이어)는 생성된 벡터를 Logit라고 불리는 더 큰 벡터에 투영하게 해주는 뉴럴 네트워크이다. 만약 10,000개의 데이터 세트로 학습했으면, Logit벡터의 크기를 10,000으로 만들고, 각 Logit벡터의 cell은 고유한 단어 점수에 해당된다.
Softmax Layer는 위에서 나온 점수들을 확률로 변환한다. 이렇게 나온 확률은 모두 양수이며, 모든 셀을 합산했을 때 1의 값을 가진다. 이 중 가장 높은 셀이 선택되고, 관련 단어가 이번 time step의 출력으로 생성된다.
▶ Review (생각)
오늘은 강의를 정리하려고 했는데, 어쩌다가 Transformer 사이트를 정리하게 됐다. 코로나 때문에 강의를 제대로 못들어서 정리가 잘 안됐던 것 같아서 교수님이 올려주신 다른 참고자료를 본 게 화근이었다. 해당 사이트는 예전에 Transformer를 공부할 때 봤던 사이트였는데, 또 보게 되니 반가웠고, 다시 보니 더 이해가 잘 되어 해당 내용으로 정리해보자는게 길어졌다.
아무튼 해당 사이트를 정리하면서 Transformer에 대해서 이제는 더 잘 이해할 수 있게 된 것 같다. '아직 확실히 이해했어'라고 얘기하기에는 조심스럽지만 그래도 꾸준히 하다보면 언젠가 해당 논문보다 더 어려운 논문을 더 쉽게 볼 수 있게 되는 날이 오지 않을까 싶다. 나중에 시간이 나면 Transformer 정리한 내용만 따로 빼서 정리해놔도 좋을 것 같다.
추가적으로 Jay Alammar님의 http://jalammar.github.io/illustrated-transformer/)사이트는 정말 Transformer에 대해 이해하기 쉽게 써놓은 사이트인 것 같다. Transformer에 대해 더 깊이 이해하고 싶다면 이 포스팅 말고 저 사이트에 들어가길 강추한다.
오늘 정리

'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 41 (0) | 2022.03.18 |
|---|---|
| [일일리포트] Day 40 (Recent Trend in NLP) (0) | 2022.03.17 |
| [일일리포트] Day 38 (0) | 2022.03.15 |
| [일일리포트] Day 37 (Transformer1) (0) | 2022.03.14 |
| [8주차] 개인 회고 (0) | 2022.03.11 |



