
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 이코테
- 최단경로
- 백준
- 개인회고
- 부스트캠프_AITech_3기
- 주간회고
- 정렬
- 구현
- 알고리즘_스터디
- Level2
- U_stage
- 단계별문제풀이
- 이진탐색
- python3
- dfs
- 기술면접
- 그리디
- 부스트캠프_AITech3기
- 알고리즘스터디
- 그래프이론
- 프로그래머스
- 백트랙킹
- mrc
- 글또
- 다시보기
- Level1
- dp
- 파이썬 3
- ODQA
- Level2_PStage
- Today
- Total
국문과 유목민
[일일리포트] Day 40 (Recent Trend in NLP) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
Recent Trendes in NLP
기존 Transformer에서 Self-Attention block을 6개만 쌓아다면 이제는 더 많이 쌓고 있다. Self-supervised Learning framework를 통해 깊게 쌓인 Transformer를 TransferLearning으로 학습해 다양한 NLP Task의 성능을 상당히 발전시킬 수 있었다. 해당 모델로는 BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA와 같은 모델이 있다.
GPT-1
다양한 Special Token(<S>, <E>, $)을 제시해서, simple한 task뿐만 아니라 자연어처리의 많은 task를 처리할 수 있는 통합된 모델을 제안했다는 것이 중요한 특징이다.
- Self-attention block을 12개를 쌓았다.
- Classification, Entailment, Similarity, Multiple Choice와 같은 다양한 Task에서 사용이 가능하다.
- Extract는 마지막에 추가하는 토큰이지만, Task에 필요한 정보들의 경우 Extract를 쿼리로 활용해 주어진 문장에서 정보를 추출할 수 있다.
- Pretrained된 모델을 활용해서 소량의 Label데이터만으로도 좋은 성능을 얻을 수 있다.
BERT
BERT(Bidirectional Encoder Representations from Transformers)
고전적인 언어모델은 왼쪽 혹은 오른쪽의 문맥만 고려했다. 하지만 알다시피 언어를 완벽히 이해하기 위해서는 양방향의 정보가 필요했다. 하지만 이를 구현하기 위해서는 '단어들이 서로를 cheating하는 문제'를 방지해야 했다 (왼쪽에서 올 때 데이터를 기억했다 오른쪽에서 올 때 해당 데이터를 사용). 따라서 BERT는 Masked Language Model(MLM)의 Task를 통해 학습하며, Large-scale 데이터와 large-scale모델을 활용한다.
MLM은 BERT의 Pretrained방법으로 input token의 몇 %를 랜덤으로 [MASK] 처리해서 학습을 진행하는 것이다. 그런데 여기서 마스킹을 너무 많이 하게 되면 문맥을 이해하기 충분하지 않고, 너무 작게 하면 train과정이 너무 오래 걸리거나 비효율적이게 됐다. BERT에서 찾은 적정 비율은 15%인데, 15%에서도 모든 단어들을 다 [MASK]처리하지 않고 그 중 80%만 [MASK]로 치환하고, 10%는 Random한 단어, 남은 10%는 단어를 바꾸지 않고 두는 방식으로 처리한다. 그 이유는 [MASK]토큰이 fine-tune하는 동안 보이지 않는 문제가 있기 때문이다.
Next Sentence Prediction(NSP) 단계는 문장 간 관계를 배우기 위한 학습방법이다. 문장 A와 B가 주어졌을 때, 문장 B가 문장 A다음에 올 수 있는 실제 문장인지 아니면 무작위 문장인지를 예측하는 방법이다.
BERT SUMMARY
- Model Architecture (L: Self-Attention Block, A: Attention Head의 개수, H: 인코딩 벡터의 차원 수)
- BASE: L = 12, H = 768, A = 12
- LARGE: L = 24, H = 1024, A = 16
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
- Learned Positional embedding
- [CLS] - Classification embedding
- Segment Embedding: 문장 레벨에서 포지션이나, 인덱스를 반영한 벡터
- Transfer Learning: 사전학습한 모델로 다양한 task를 수행할 수 있다.
- Pre-Training Tasks
- MLM (Masked Language Model)
- NSP (Next Sentence Prediction)
BERT vs GPT-1
- Training-data size: BERT는 2500M words, GPT는 800M wods
- Trainig special tokens during training: BERT는 [SEP], [CLS]사용하고. 여러 문장이 주어졌을 때, 각 문장별로 인덱스를 나타낼 수 있는 segment embedding을 수행한다.
- Batch size: BERT - 128,000 words, GPT - 32,000 words. BERT가 더 많은 단어를 불러와서 학습을 진행한다. BERT는 Batch가 커질 수록 학습이 더 잘되는 모습을 보여준다. 하지만 그만큼 더 많은 GPU와 메모리를 필요로 한다.
- Task-specific fine-tuning: GPT는 5e-5로 같은 lr을 사용했지만, BERT는 task별로 다른 learning rate를 사용한다.
- GLUE banch mark: BERT가 더 좋은 성능을 보여준다.
- MRC(Machine Reading Comprehension), Question Answering task에 대해 좋은 성능을 보여준다.
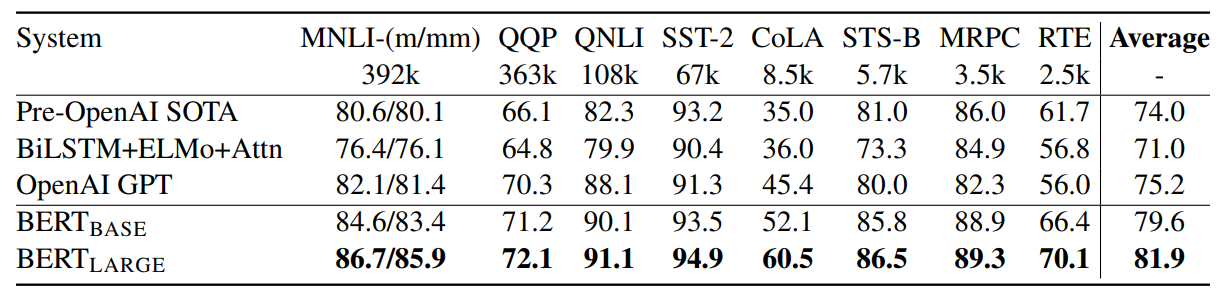
- BERT의 레이어를 깊게 쌓고 파라미터를 여러 개 만들어 DownStream task에 접목시켰을 때 성능이 더 향상된다고 전망한다.
SQuAD
스탠포드에서 만든 Question Answering Dataset이다. 랜덤한 위키에서 내용을 가지고 와서 질문과 답변을 생성해내는 Task를 수행하는데 사용되는 데이터셋이다. BERT는 해당 Task에서 좋은 성능을 보여줬다. SQuAD 2.0에서는 답이 없는 질문에 대한 정보가 추가되었는데, 해당 Task에서도 좋은 성능을 보여줬다.
GPT-2
단지 엄청 큰 Transformer Language Modeling(다음 단어 예측) Task를 수행하는 모델이라고 할 수 있다. 40GB의 선별된 좋은 퀠리티의 Train Text를 활용했다. Language Model을 이용해서 down-stream task에서 zero-shot stting(일반적으로 관찰된 클래스와 관찰되지 않은 클래스를 어떤 형태의 보조 정보를 통해 연관시킴으로써 작동하며, 이는 관찰 가능한 개체 식별 속성을 인코딩합니다)으로도 다뤄질 수 있다는 잠재적인 능력을 보여줬다.

- Byte pair encoding(BPE): 서브워드 레벨에서의 임베딩을 진행
- Modification(차이점): Layer가 위로 갈 수록 선형변환이 더 0에 가까워질 수록 작성을 했다. 그리고 최종 Self Attention block 후에 Layer Normalization이 추가됐다.
- Question Answering: Conversation question answering dataset(CoQA)에서 Finetune없이 테스트 결과 55% F1-Score를 달성함으로써 가능성을 보였다.
- Summarization:CNN and Daily Mail Dataset
- Translation: WMT14 en-fr dataset
GPT-3
GPT-3 (Language Models are Few-SHot Learners, NeurlPS'20)는 GPT-2에 비교할 수 없을 정도로 Self-Attention블록을 많이 쌓았다. 그리고 Zero-shot보다 example을 사이에 넣어 One-shot이나 Few-shot으로 진행해 성능을 향상시켰다.
Zero-shot의 경우 과제에 대한 description만 주어지는데, One-Shot처럼 Example을 하나 제공해주거나 약간의 Few-shot을 제공해줌으로써 성능을 향상시킬 수 있었다.
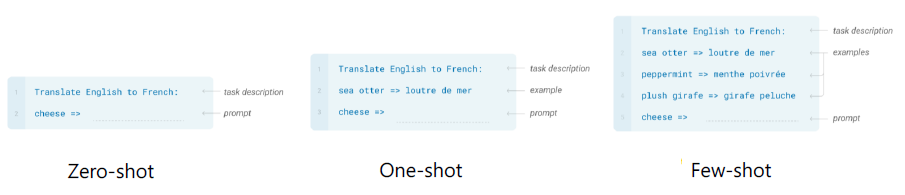
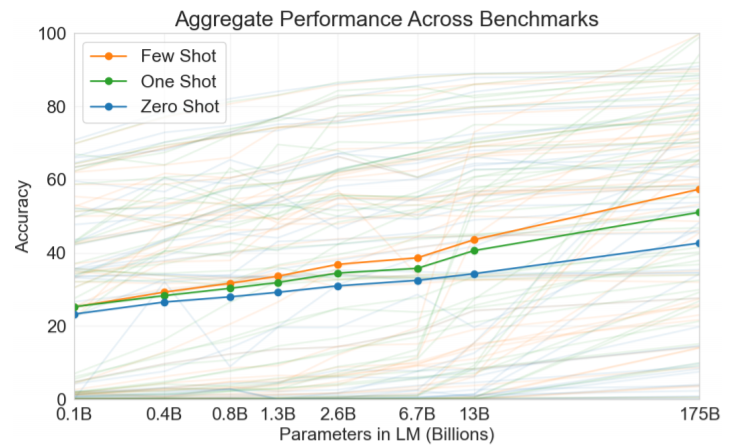
ALBERT
ALBERT(A Lite BERT for Self-supervised learning of Language Representations, ICLR’20)모델은 기존 BERT모델이 가지는 큰 덩치로 생기는 문제(메모리 제한, Training Speed한계)를 극복하기 위하고자 등장했다. 성능의 하락없이 모델의 사이즈와 학습 시간을 줄이는 새로운 Selfsupervised learning의 Pretraining Task를 제안했다.
- Factorized Embedding Parameterization
- Cross-layer Parameter Sharing
- (For Performance) Sentence Order Prediction
Factorized Embedding Parameterization
Embedding레이어의 dimension을 줄이는 방법을 다음과 같이 제안했다. Embedding 단계에서 아래 그림과 같이 4차원을 갖는 경우, Low-Level Vectorization이라는 기법을 활용해서 2차원 벡터에다가 하나의 Layer를 추가해서 전체적인 파라미터의 수를 줄이고자 했다. 이렇게 할 경우 실제적으로 파라미터의 개수가 줄어들게 된다. 조금 더 수치를 키워 계산해보자면 (500x100)의 → (500x15+15x100)으로 바뀌게 되고 필요한 파라미터의 개수는 50,000에서 9,000으로 줄어들게 된다.
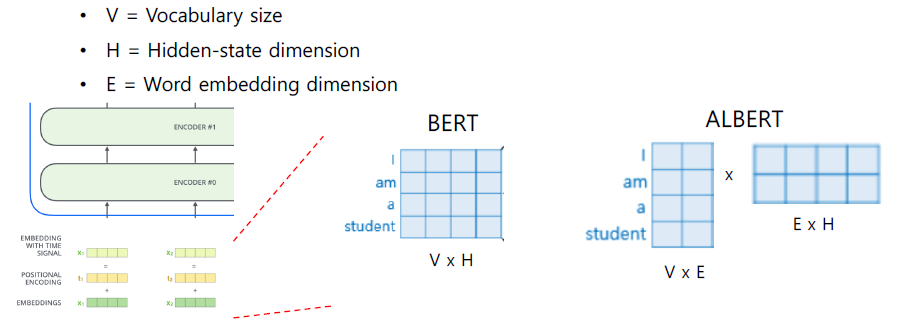
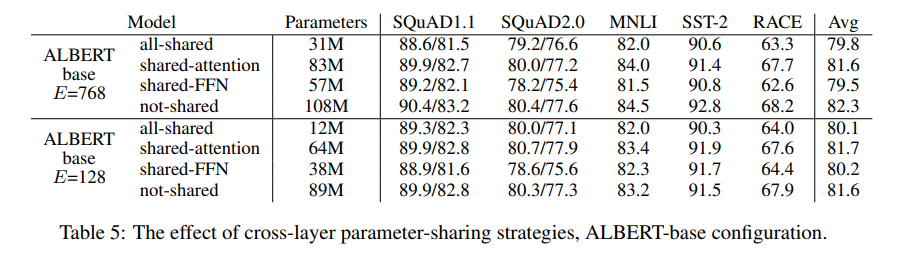
Cross-layer Parameter Sharing
이전까지는 선형변환을 위한 매트릭스들을 각 층별로 생성했는데, 이를 Shaerd되는 하나의 파라미터 set으로 구성하고자 했다. 그래서 Transformer Encoder의 구성 Layer인 FFN이나 Attention Layer를 shared하게 구성해서 실험을 했을 때 실제적으로 성능의 저하가 크지 않았다는 결과를 얻을 수 있었다.
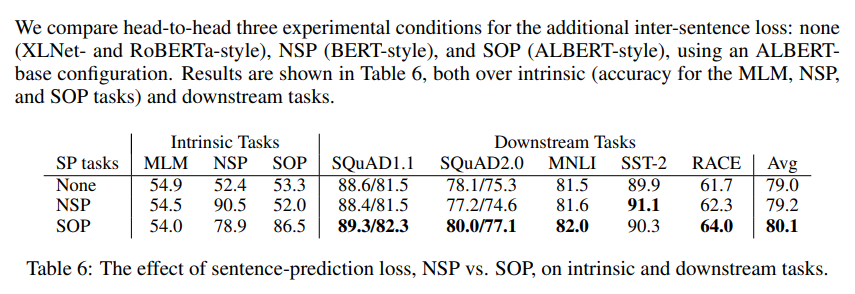
Sentence Order Prediction (SOP)
BERT의 Next Sentence Prediction(NSP) Task는 BERT에게 너무 쉬운 Task였기에 Pretrain과정에서 실효성이 없다고 생각해 이를 대신해서 다른 학습 방법을 제시했다. 두 단어의 위치를 바꿔 정방향 순서인지 역방향 순서인지 예측하고자 했는데, 이렇게 함으로써 성능을 올릴 수 있다.
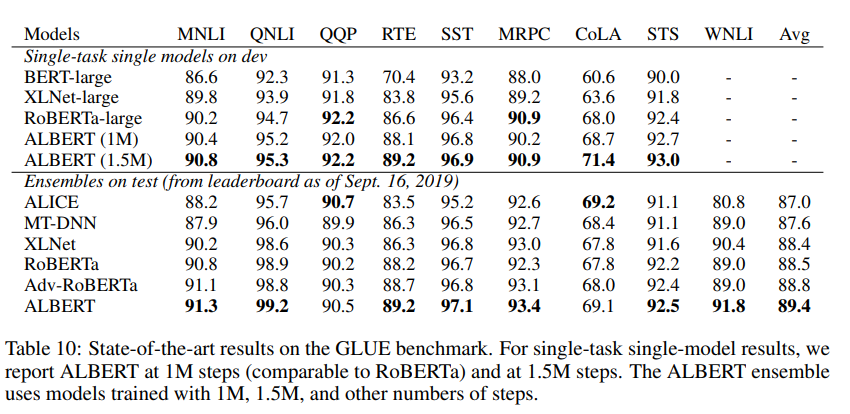
최종적으로 GLUE Results를 봤을 때도 ALBERT모델이 다른 모델들보다 좋은 성능을 보여주고 있다는 것을 확인할 수 있다. ALBERT는 다른 모델들보다 파라미터의 수를 줄여서 무게를 낮췄음에도 성능을 올릴 수 있었다는 점에서 꽤 고무적이다.
ELECTRA
ELECTRA(Pre-training Text Encoders as Discriminators Rather Than Generators, ICLR’20)는 Efficiently Learning an Encoder that Classifies Token Replacements Accurately라는 말처럼 실제 입력 토큰과 비슷하지만 합성적으로 생성된 대체 토큰을 구별하는 방법을 배우면서 학습을 하는 모델이다.
Discriminator는 GAN(generative adversarial network)의 아이디어에서 착안했다. Masked 단어를 복원해주는 Generator라는 부분과 해당 단어가 예측된 단어인지 원래 있던 단어인지를 구분하는 Discriminator라는 부분을 둔 모델이다. 여기서 Generator는 BERT모델로 볼 수 있고, 그리고 Discriminator를 ELECTRA로 볼 수 있다.
입력으로 들어온 데이터를 ground-truth데이터로 활용해 generator로 나온 데이터와 비교해서 예측을 하면서 학습을 진행한다. Discriminator를 Pre-trained된 모델로 사용하게 된다(Discriminator가 메인).
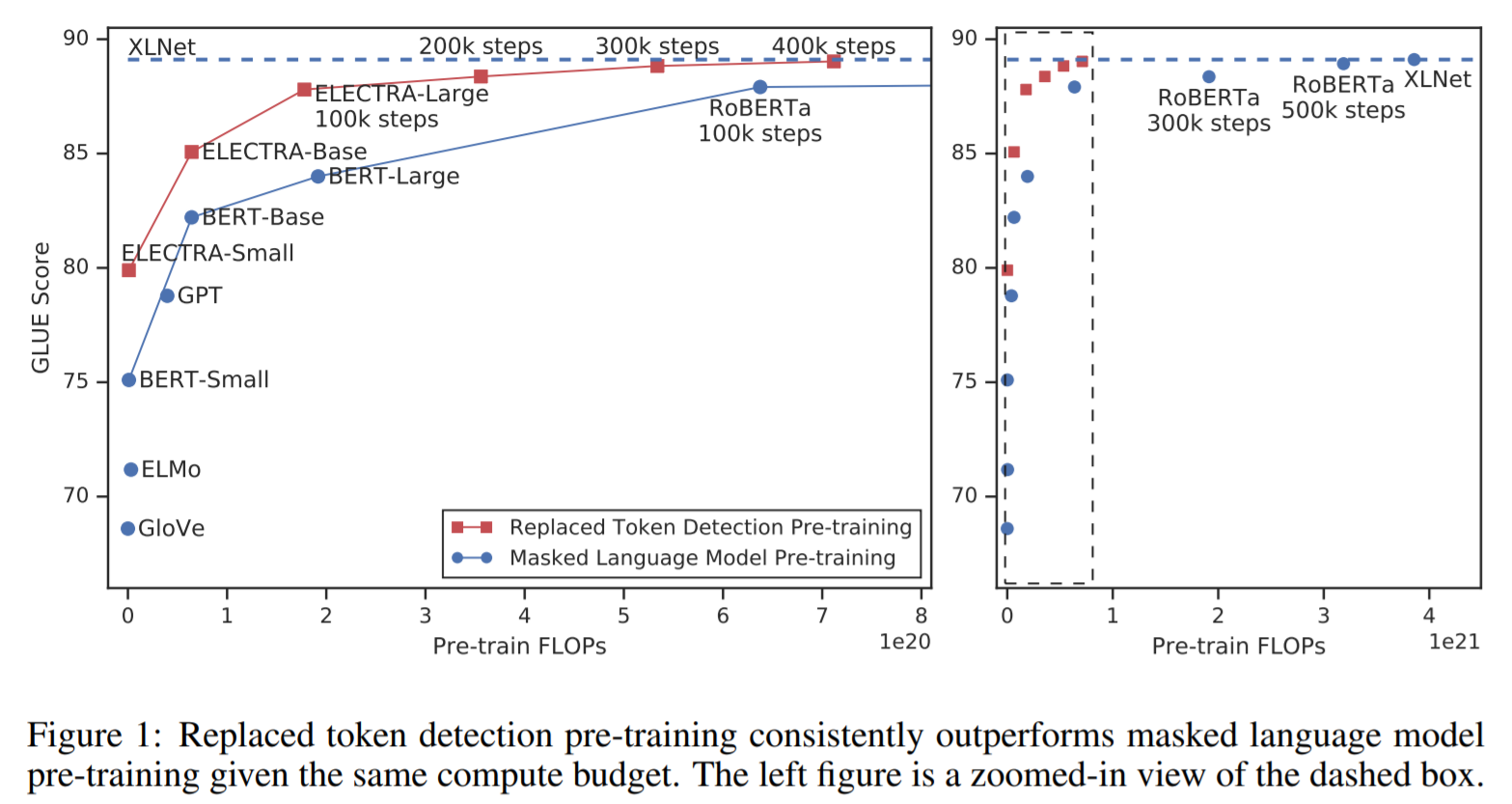
Light-weight Models
기존 모델들이 Self-Attention block을 많이 쌓아서 성능을 올리려고 했기에 실제 다양한 연구에서 현업에 활용하기 어려운 부분이 있었다. 파라미터의 수를 줄이면서도 성능을 올릴 수 있는 경량화 모델에 대한 연구에 초점이 맞춰져있다.
Distill BERT
Knowledge Distillation 테크닉을 활용해서 BERT를 경량화 한 모델이다. Teacher Model의 Target Distribution을 모사해서 이를 Ground-Truth로 해서 Softmax loss를 적용해 Teacher Model을 닮도록 Student Model을 학습하도록 하는 방법이다. 이렇게 함으로써 Student모델이 Teacher모델의 행동, 예측 등을 재현하게 한다. 이런 방법이 바로 knowledge Distillation이다.
Tiny BERT
Distill BERT처럼 Knowledge Distillation 테크닉을 활용해 기본적으로 softmax loss가 같아지게 한다. 하지만 더 나아가 Embedding Layer, 각 Self Attention Block이 가지는 $W_q W_k W_v$등의 Atention Matrix 그리고 결과로 나오는 Hidden State 벡터까지도 유사해지도록 중간 결과물까지 Student Network가 담도록 학습을 진행한다. 이 경우 MEE Loss를 통해 학습을 진행하게 되는데, Student Vector는 Teacher Vector보다 차원이 낮아진다. 따라서 최대한 유사해지도록 하기 위해 Teacher와 Student 사이에 FC Layer를 하나 둬서 Dimension간의 Missmatch를 해결했다.
Fusing Knoledge Fraph into Language Model
BERT는 주어진 문장에 포함되어있지 않은 데이터에 대한 질문이 들어올 경우에는 잘 대답하지 못하는 문제가 발생했다. 따라서 세상의 개념이나 개체들을 정형화해서 만들어준 Knowledge graph를 활용해서, 외부 지식을 필요로 하는 부분에 대해 취약점을 극복하고자 한다. 따라서 이를 어떻게 하면 BERT와 잘 적용시킬 수 있을 지에 대한 연구가 진행되고 있다.
- ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
- KagNET: Knowledge-Aware Graph Networks for Commonsense Reasoning (EMNLP 2019)
▶ Review (생각)
오늘은 강의랑 과제를 일찍 끝내서 비교적 시간이 많다고 생각이 되어 NLP 마지막 2강의에 대해서 좀 길게 정리를 해봤다. 해당 강의에서 NLP의 트렌드를 다루고 있었기 때문에 잘 정리해두면 좋겠다는 생각을 했다. BERT와 GPT시리즈부터 ALBERT나 ELECTRA 그리고 BERT에서 더 나아가 어떤 방식으로 더 모델을 개선하려고 하는 지까지 포괄적으로 배울 수 있었다. 각 모델들에 대해 더 자세히 알기 위해서는 논문을 보는게 가장 좋은 방법이겠지만, 이렇게 여러 핵심 모델들과 동향에 대해서 다뤄주신 것만으로도 큰 흐름을 이해하기에는 충분했다고 생각한다.
강의 내용을 정리하고 난 이후 피어세션과 오피스아워에서는 과제에 대해서 리뷰를 진행했다. 오피스아워에서 내 코드와 다른 부분들이 있어 집중해 들으려고 했지만 약을 먹고 난 이후라서 잘 집중하지 못했었다. 내일 녹화본이 올라오면 다시 한 번 보고 저번처럼 좋은 코딩 방법에 대해서는 따로 기록해둬야겠다.
부캠 강의 이후에는 내일 논문 리뷰를 해야해서 논문을 읽고, 자료를 만들었는데 자료의 경우 유튜브에서 좋은 강의를 발견해서 해당 강의를 토대로 정리하고자 한다. 논문 리뷰 내용을 블로그에 따로 정리하면서 같이 발표 준비를 해도 좋을 것 같다는 생각이 든다. 내일은 과제 리뷰와 피어세션 논문 세미나 준비를 주로 할 것 같다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [9주차] 개인 회고 (0) | 2022.03.18 |
|---|---|
| [일일리포트] Day 41 (0) | 2022.03.18 |
| [일일리포트] Day 39 (Transformer2) (0) | 2022.03.16 |
| [일일리포트] Day 38 (0) | 2022.03.15 |
| [일일리포트] Day 37 (Transformer1) (0) | 2022.03.14 |



