
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 백트랙킹
- 기술면접
- python3
- dfs
- 이코테
- dp
- 알고리즘_스터디
- U_stage
- ODQA
- 파이썬 3
- 그래프이론
- 구현
- 주간회고
- 부스트캠프_AITech_3기
- 그리디
- 알고리즘스터디
- mrc
- 백준
- 프로그래머스
- 부스트캠프_AITech3기
- 개인회고
- 다시보기
- 글또
- 단계별문제풀이
- Level1
- Level2_PStage
- Level2
- 이진탐색
- 정렬
- 최단경로
- Today
- Total
국문과 유목민
[일일리포트] Day 43 (단일 문장 분류) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
BERT Pre-Training
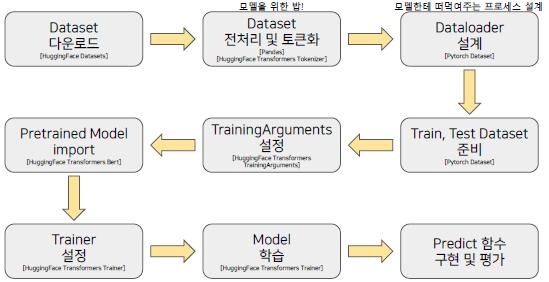
BERT모델 학습을 하는 단계는 다음과 같다.
1. Tokenizer만들기
2. 데이터셋 확보
3. Next Sentence Prediction(NSP)
4. Masking
이미 있는 모델이 아닌 새로운 모델로 학습을 해야 하는 이유는 특정 도메인 Task에 대해. 도메인에 특화된 학습 데이터만 사용하는 것이 기존의 BERT를 Finetuning하는 것보다 성능이 더 좋게 나온다.
그리고 현업에 들어가면 도메인에 특화된 데이터를 다루게 될 것이다. 해당 도메인에 관련된 코퍼스를 가지고 학습해야 야 더 좋은 성능을 기대할 수 있다. BERT를 학습하기 위해서는 Dataset과 DataLoader가 필요하다. Dataset은 모델에게 줄 밥을 만드는 과정이고, DataLoader는 어떻게 밥을 먹일 지에 관한 것이다.
BERT언어모델 기반_단일문장분류
의존 구문 분석
단어들 사이의 관계를 분석하는 Task이다. 어순과 생략이 자유로운 한국어와 같은 언어에서 주로 연구된다. 의존소와 지배소로 나뉜다. 의존 구분 분석은 복잡한 자연어 형태를 그래프로 구조화해서 표현함으로써 각 대상에 대한 정보 추출이 가능하다.
- 지배소: 의미의 중심이 되는 요소
- 의존소: 지배소가 갖는 의미를 보완해주는 요소 (수식)
분류 규칙은 다음과 같다. 지배소는 후위 언어로 항상 의존소보다 뒤에 위치한다. 각 의존소의 지배소는 하나이며, 교차 의존 구조는 없다. 분류 방법은 Sequence Labeling방식으로 처리 단계를 나눈다. 앞 어절에 의존소가 없고, 다음 어절이 지배소인 어절을 삭제하며 의존 관계를 형성한다.
의존 구문 분석에 대한 추가적인 정보를 알고 싶다면 다음 논문(의존 구문분석을 위한 한국어 의존관계 가이드라인 및 엑소브레인 언어분석 말뭉치)을 살펴보면 도움이 될 것이다. (의외로 설명이 친절하기 때문에 읽어보면 좋을 것 같다. )
단일 문장 분류 Task
단일 문장 분류는 주어진 문장이 어떤 종류의 범주에 속하는지를 구분하는 task를 말한다.
1. 감성분석(Sentiment Analysis): 문장의 긍정 또는 부정 및 중림 등 성향을 분류하는 프로세스이다. 기업모니터링이나 혐오발언 분류 등의 Task에 사용할 수 있다.
- 혐오 발언 분류: 댓글, 게임 대화 등 혐오 발언을 분류하여 조치를 취하는 용도
- 기업 모니터링: 소셜, 리뷰 등 데이터에 대해 기업 이미지, 브랜드 선허도, 제품평가 등 긍부종 요인을 분석
2. 주제 라벨링(Topic Labeling): 문장의 내용을 이해하고 적절한 범줄르 분류하는 프로세스이다. 주제별로 뉴스 기사를 구성하는 등 데이터 구조화와 구성에 용이하다. 대용량 문서 분류나 VoC 등에 사용할 수 있다.
- 대용량 문서 분류: 대용량의 문서를 범주화
- VoC(Voice of Customer): 고객의 피드백을 제품 가격, 개선점, 디자인 등 적절한 주제로 분류하여 데이터를 구조화
3. 언어감지: 문장이 어떤 나라 언어인지를 분류하는 프로세스
- 번역기: 번역할 문장에 대해 적절한 언어을 감지함
- 데이터 필터링: 타겟 언어 이외 데이터는 필터링
4. 의도 분류(Intent Classification): 문장이 가진 의도를 분류하는 프로세스이다. 입력 문장이 질문, 불만, 명령과 같은 다양한 의도를 가질 수 있기 때문에 적절한 피드백을 줄 수 있는 것으로 라우팅 작업이 가능하다.
- 챗봇: 문장의 의도인 질문, 명령, 거절 등을 분석하고 적절한 답변을 주기 위해 활용
문장 분류를 위한 한국어 데이터
- Kor_hate: 혐오 표현에 대한 데이터
- Kor_Sarcasm: 비꼬지 않은 표현의 문장과 비꼬는 표현의 문장 (욕설이나 긍부정으로 태그되지 않는다.)
- Kor_sae: 예/아니오로 답변 가능한 질문, 대안 선택을 묻는 질문, Wh-질문, 금지 명령, 요구 명령 등을 분류
- Kor_3i4k: 단어 또는 문장 조각, 평서문, 질문, 명령문 등 분류
해당 데이터 뿐만 아니라 다양한 한국어 데이터셋을 datasets라이브러리를 통해 사용할 수 있다.
단일 문장 분류 모델 학습
BERT의 [CLS] 토큰의 벡터를 Classification하는 Dense Layer를 사용한다. 주요 매개변수는 다음과 같다. (매번 나올 매개변수이기 때문에 아예 외워두는 것도 좋아 보인다)
- input_ids : sequence token을 입력
- attention_mask : [0,1]로 구성된 마스크이며 패딩 토큰을 구분
- token_type_ids : [0,1]로 구성되었으며 입력의 첫 문장과 두번째 문장 구분
- position_ids : 각 입력 시퀀스의 임베딩 인덱스
- inputs_embeds : input_ids대신 직접 임베딩 표현을 할당
- labels : loss 계산을 위한 레이블
- Next_sentence_label : 다음 문장 예측 loss 계산을 위한 레이블
학습 과정
BERT모델은 어떤 모델이든 다음과 같은 과정을 거쳐서 생성과 학습이 진행된다. (BERT모델이 아니어도 대부분의 모델이 다음과 같은 프로세스를 기본적으로 가진다)
▶ Review (생각)
이번 주 강의는 NLP Task에 대해서 전반적으로 잘 다뤄주시는 것 같아 만족도가 높다. 특히 실습 코드를 통해 수업을 진행하시다보니 수업에 집중하기도 수월하고, 조금 더 직관적으로 이해할 수 있는 것 같다. 이번 주에 배운 실습 코드들만 잘 이해해서 내 것으로 만들기만 해도 큰 성장을 할 수 있을 것 같다. 시간이 남는대로 해당 코드들을 정리하면 좋을 것 같다.
강의는 2개 정도 남아서 내일 프로젝트를 시작하려고 한다. 프로젝트를 진행하면서 팀원들과 의견 교환을 열심히 하고, 어떤 일을 하든 해당 일을 왜 하는지에 대해 이유를 설명할 수 있어야 한다. 멋있고 복잡해보이는 기술보다, 설명할 수 있는 근거가 확실한 Task가 더 매력적으로 보일 수 있다는 것을 기억하자.
그리고 오늘로 코로나로 아팠던 게 다 사라진 것 같다. 그래서 저번 주부터 시작했어야 할 자소서 작성이나 코딩테스트 준비 등을 해봐야겠다는 생각을 했다. 일단, 거의 일주일동안 기존의 규칙적인 삶을 살지 못했었기에 다시 루틴에 적응해야겠다. 오늘만 해도 운동을 다녀왔는데 꽤나 지쳤었다... 지치지 말고 천천히, 대신 확실하게 해야겠다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 45 (Level2_PStage_1) (1) | 2022.03.24 |
|---|---|
| [일일리포트] Day 44 (두 문장 관계 분류) (0) | 2022.03.23 |
| [일일리포트] Day 42 (NLP 개괄, 전처리, BERT) (0) | 2022.03.21 |
| [9주차] 개인 회고 (0) | 2022.03.18 |
| [일일리포트] Day 41 (0) | 2022.03.18 |



