
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Level2
- dp
- 알고리즘_스터디
- 알고리즘스터디
- 백준
- Level2_PStage
- 그래프이론
- 기술면접
- 백트랙킹
- python3
- mrc
- 부스트캠프_AITech3기
- 정렬
- dfs
- 주간회고
- 단계별문제풀이
- 프로그래머스
- 이코테
- U_stage
- 다시보기
- Level1
- 이진탐색
- 개인회고
- 그리디
- 글또
- 파이썬 3
- ODQA
- 구현
- 최단경로
- 부스트캠프_AITech_3기
- Today
- Total
국문과 유목민
[일일리포트] Day 42 (NLP 개괄, 전처리, BERT) 본문

해당 일일리포트에서는 네이버 커넥트에서 진행하는 '부스트캠프 AI Tech 3기'에서 배운 내용을 다루고 있습니다. 저작권 이슈 때문에 관련 자료를 올릴 수는 없기에 핵심 이론과 코드를 요약해서 올리고 있기에 내용이 부족할 수 있습니다.
▶ Today I Learned (핵심 요약 정리)
인공지능과 자연어 처리 (NLP Overview)
해당 내용은 별도의 포스팅으로 정리했습니다. 다음 포스팅 참조 [NLP OVERVIEW (Word2Vec to Transformer)]
자연어 전처리
원시 데이터를 기계 학습 모델이 학습하는데 적합하게 만드는 프로세스를 의미한다. 데이터 자체가 문제가 있다면 좋은 성능을 기대하기 어렵기 때문에 자연어 전처리는 Task의 성능을 가장 확실하게 올릴 수 있는 방법이다.
자연어 처리는 'Task설계 - 필요 데이터 수집 - 통계학적 분석 - 전처리 - Tagginng - Tokenizing - 모델 설계 - 모델 구현 - 성능 평가 - 완료' 의 단계를 거친다. 그 중 몇 가지 Task에 대해서 알아보도록 하겠다.
- 통계학적 분석: Token 개수 → 아웃라이어 제거, 빈도 확인 → 사전정의
- 전처리:
- 개행문자 제거, 특수문자 제거, 공백 제거
- 중복 표현 제어 (ㅋㅋㅋㅋㅋ, ㅠㅠㅠㅠ, …)
- 이메일, 링크 제거, 제목 제거
- 불용어(의미가 없는 용어) 제거, 조사 제거
- 띄어쓰기, 문장분리 보정
- Tokenizing: 주어진 데이터를 토큰이라 불리는 단위로 나누는 작업. 토큰이 되는 기준은 다를 수 있다.
- 어절 tokenizing
- 형태소 tokenizing
- WordPiece tokenizing
Python String 관련 함수
전처리를 하기 위해서는 다양한 Python String 함수를 익혀놓을 필요가 있다.
다음 포스팅 참조 [Python String 관련 함수]
Python String 관련 함수
국문과 유목민 Python String 관련 함수 본문 Prev 1 2 3 4 5 ··· 211 Next
cold-soup.tistory.com
BERT 언어모델
BERT모델 이전에 Seq2SEq → Attention+Seq2Seq → Transformer(가장 최근)가 존재했다. BERT는 Transformer를 활용한 모델이다.

BERT는 입력된 이미지 자체에 masking을 해서 복원이 어려운 문제를 만든다. 그리고 모델이 이를 학습하게 함으로써 더 좋은 학습 결과를 얻고자 한다. (이후 나올 GPT-2는 입력의 반을 자르고 뒤 반을 예측하게 한다)

- 2개의 TokenSequence를 학습에 사용한다.
- WordPiece Tokenizing을 사용한다.
- Masking과정을 진행한다. CLS, SEP토큰을 제외하고, 15%를 랜덤하게 뽑는다. 그리고 그 중에서도 80%는 마스킹, 10%는 랜덤하게, 10%는 아무것도 바꾸지 않는다.

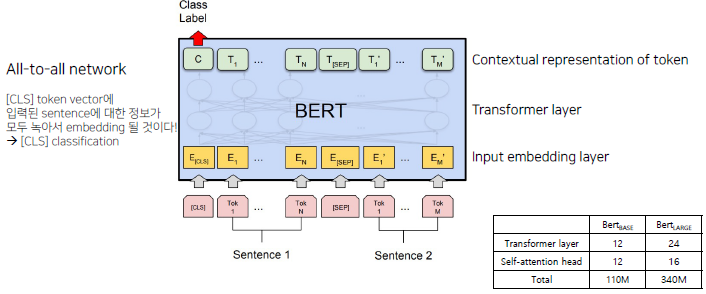
모델 구조도
BERT는 Transformer layer12개로 이루어져 있으며, All-to-all network로 연결되어 있다. [SEP]토큰과 [CLS]토큰이 사용된다. [SEP]토큰은 sentence1과 sentence2를 나누는 토큰이고, [CLS]토큰은 sentence1과 sentence2가 서로 연관된 sentence인지 확인하기 위해 사용한다.
BERT에서는 [CLS]토큰이 sentence1과 sentence2를 포괄하고 있는 어떤 벡터로 녹아든다고 가정을 한다. 그리고 [CLS]토큰이 이 sentence들(sentence1, 2)을 잘 표현하기 위해 [CLS]토큰 위에 classification layer를 붙여 pretrain을 진행하게 된다.
NLP 실험
Input만 다르게 주면 BERT모델 하나만 가지고도 아래와 같은 Task들을 수행할 수 있다. Task에 맞춰서 별도의 Tokenizing을 진행해야 한다. 언어모델을 활용할 때, feature를 어떤 것으로 활용할 지를 계속 생각해야 한다. 그리고 이를 통해 어떻게 Tokenizing할 지에 대해서 생각해야 한다.

단일 문장 분류
- 감성 분석: 주어진 문장이 긍정인지 부정인지를 분석
- 관계 추출: Entity(관계 추출의 대상이 되는 존재), Entity인 sbj와 obj 한 Pair와 문장이 주어질 때 해당 Pair의 관계가 어떻게 되는지를 추측
두 문장 관계 분류
- 의미 비교: 주어진 두 문장의 의미가 유사한 지를 분류
문장 토큰 분류
- 개체명 분석 (NER): 주어진 워드의 개체명을 분류
기계 독해 정답 분류
- 기계 독해
ETRI KoBERT의 tokenizing 모델: 형태소 단위로 분리를 먼저 수행하고, 분리된 것을 바탕으로 한 번 더wordpiece를 Tokenizing 수행한 모델. 한국어에 맞게 Tokenizing했다는 의미에서 성능이 매우 좋았다고 한다. 하지만 이를 활용하려면 ETRI 형태소 분석기를 사용해야 한다.
현재까지는 한국어 모델에서는 형태소 Tokenizing을 하고 wordpiece를 태운 모델의 성능이 가장 좋다고 한다.
▶ Review (생각)
이번 주부터 Level2 Pstage가 시작됐다. KLUE데이터셋을 활용한 문장 관계분류 Task에 관한 프로젝트로 3주간 진행될 예정이다. 하지만 아직까지 해당 Task에 대한 이해가 부족해서 우선 강의를 다 듣고 나서 이해를 한 이후 프로젝트를 진행하자고 팀원들과 합의를 했다.
사실 이번 P-Stage기간 동안의 강의에 대해 크게 기대하지 않았었는데 듣다보니 너무 좋았다. 그래서 뭔가 잘 정리해두고 싶다는 생각이 들었다. NLP의 전체적인 프로세스를 다룬 첫 번째 강의를 별도의 포스팅으로 정리해뒀고, 전처리나 BERT모델에 대한 강의도 최대한 깔끔하게 정리해보고자 했다. 그리고 해당 강의의 내용도 좋았지만 실습 코드의 내용이 더 좋아서 코드의 내용도 별도로 정리를 하고 싶어 강의를 빠르게 듣고, 해당 내용도 별도의 포스팅으로 정리해야겠다.
'IT 견문록 > 2022_부스트캠프 AITech 3기(100일)' 카테고리의 다른 글
| [일일리포트] Day 44 (두 문장 관계 분류) (0) | 2022.03.23 |
|---|---|
| [일일리포트] Day 43 (단일 문장 분류) (0) | 2022.03.22 |
| [9주차] 개인 회고 (0) | 2022.03.18 |
| [일일리포트] Day 41 (0) | 2022.03.18 |
| [일일리포트] Day 40 (Recent Trend in NLP) (0) | 2022.03.17 |



